

这篇文章主要从技术视角介绍下跨平台WebCanvas的架构设计以及一些关键模块的实现方案(以Android为主),限于作者水平,有不准确的地方欢迎指正或者讨论。
设计目标
标准化:Web Canvas标准主要指的是W3C的Canvas2D和WebGL。标准化的好处一方面是学习成本低,另一方面上层的游戏引擎也可以以很低的适配成本得到复用;
跨平台:跨平台主要目地是为了扩宽使用场景、提升研发效率、降低维护成本;
跨容器: 由于业务形态的不同,Canvas需要能够跑在多种异构容器上,如小程序、小游戏、小部件、Weex等等;
高性能: 正所谓「勿在浮沙筑高台」,上层业务的性能很大程度取决于Canvas的实现;
可扩展: 从下文的Canvas分层设计上可以看到,每一层的技术选型都是多样化的,不同场景可能会选择不同的实现方案,因此架构上需要有一定的可扩展性,最好能够做到关键模块可插拔、可替换。
Canvas渲染引擎原理概览
▐ 工作原理
工作原理其实比较简单,一句话就可以说明白。首先封装图形API(OpenGL、Vulkan、Metal...)以支持WebGL和Canvas 2D矢量图渲染能力,对下桥接到不同操作系统和容器之上,对上通过language binding将渲染能力以标准化接口透出到业务容器的JS上下文。
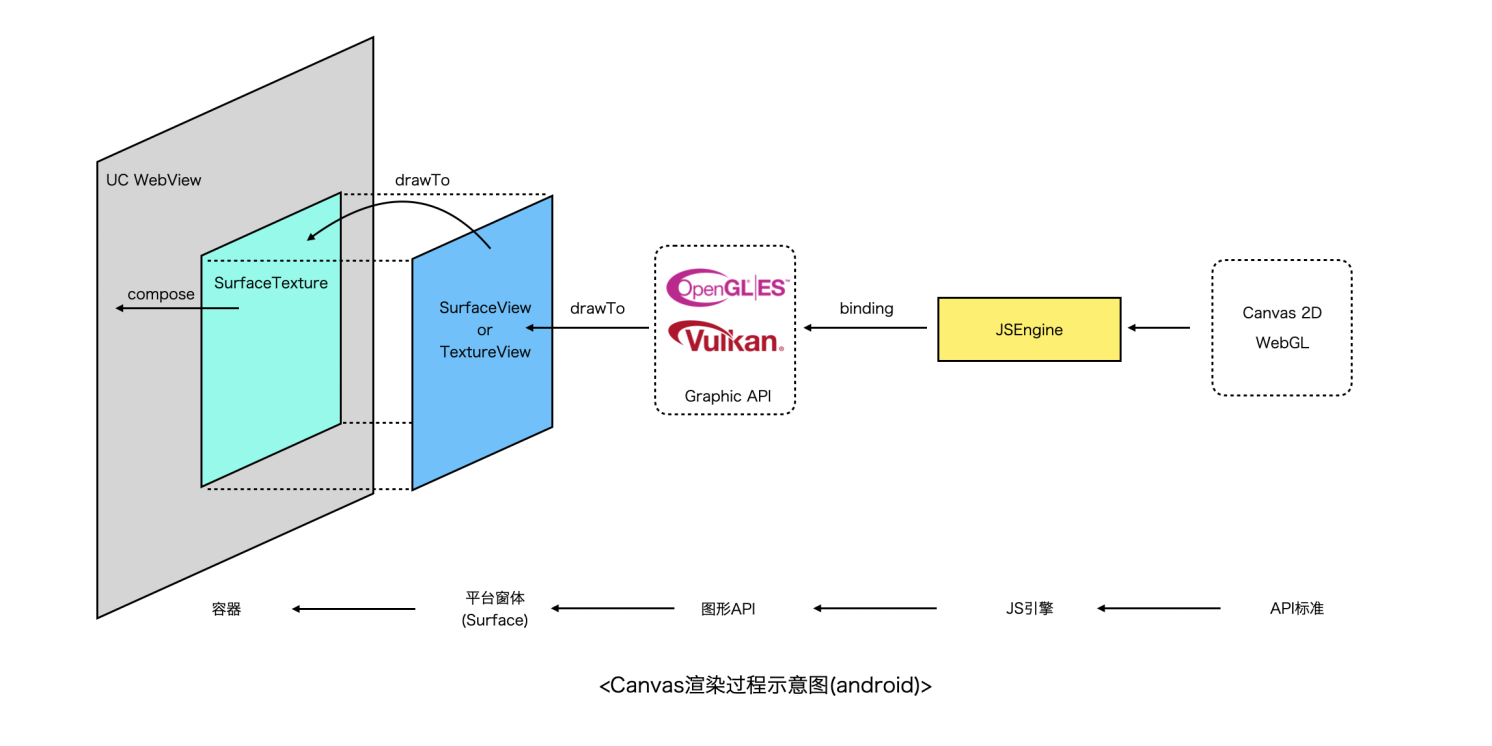
举个例子,以下是淘宝小程序容器Canvas组件的渲染流程,省略了「亿」点点细节。
Canvas在Android上其实是一个SurfaceView/TextureView,通过同层渲染的方式嵌入到UCWebView中。开发者调用Canvas JS接口,最终会生成一系列的渲染指令送到GPU,渲染结果写入图形缓冲区,在合适时机通过SwapBuffer交换缓冲区,然后操作系统进行图层合成和送显。
▐ 分层架构
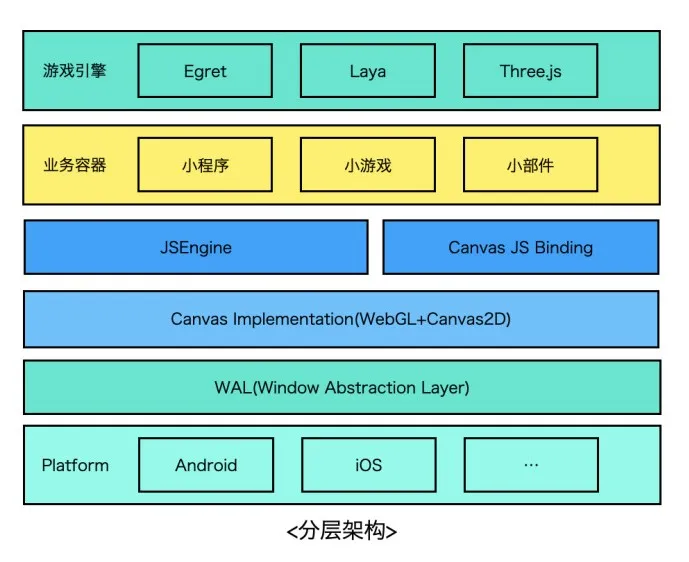
从业务形态上看,不管是小程序、小游戏还是其他容器,实现上都是相似的,如下图所示,通过JSBinding实现标准Canvas接口,开发者可以通过适配在上面跑web游戏引擎(laya、egret、threejs...),下边是JS引擎,这一层可以有不同的技术选型,如老牌的V8、JSC,后起之秀quickjs、hermes等等,在这之下就是Canvas核心实现了,这一层需要分别提供WebGL、Canvas2D的能力。WebGL较为简单,基本与OpenGLES接口一一对应,简单封装即可。
Canvas 2D如果要从零开始实现的话相对来说会复杂一些(特别是文字、图片、路径的渲染等),不过技术选型上仍然有很多选择比如cairo、skia、nanovg等等,不管使用哪种方案,只要是硬件渲染,其backend只有vulkan/OpenGLES/metal/Direct3D等几种选择。
目前OpenGL使用最为广泛,还可以通过google的Angle项目适配到vulkan/directx等不同backend上。Canvas实现层之下是WAL窗体抽象层,这一层的职责就是为渲染提供宿主环境,通过EGL/EAGL等方式绑定GL上下文与平台窗体系统。下文将对相关模块的实现分别进行介绍。考虑到性能、可移植性等因素,除了与平台/容器桥接的部分需要使用OC/Java等语言实现之外,其余部分基本采用C++实现。
JS Binding机制
JS引擎通常会抽象出VM、JSContext、JSValue、GlobalObject等概念,VM代表一个JS虚拟机实例,拥有独立的堆栈空间,有点类似进程的概念,不同的VM相互是隔离的(因此在v8中以v8::Isolate命名),一个VM中可以有多个JSContext,JSContext代表一个JS的执行上下文,可以执行JS代码,JSValue代表一个JS值类型,可以是基础数据类型也可以是Object类型,每个JSContext中都会拥有一个GlobalObject对象,GlobalObject在JSContext整个生命周期内,都可以直接进行访问,它默认是可读可写的,因此可以在GlobalObject上绑定属性或者函数等,这样就可以在JSContext执行上下文中访问它们了。
要想在JS环境中使用Canvas,需要将Canvas相关接口注入到JS环境,正如Java JNI、Python Binding、Lua Binding等类似,JS引擎也提供了Extension机制,称之为JS Binding,它允许开发者使用c++等语言向JS上下文中注入变量、函数、对象等。
// V8函数绑定示例
static void LogCallback(const v8::FunctionCallbackInfo<v8::Value>& args){...}
...
// Create a template for the global object and set the
// built-in global functions.
v8::Local<v8::ObjectTemplate> global = v8::ObjectTemplate::New(isolate);
global->Set(v8::String::NewFromUtf8(isolate, "log"),
v8::FunctionTemplate::New(isolate, LogCallback));
// Each processor gets its own context so different processors
// do not affect each other.
v8::Persistent<v8::Context> context =
v8::Context::New(isolate, nullptr, global);
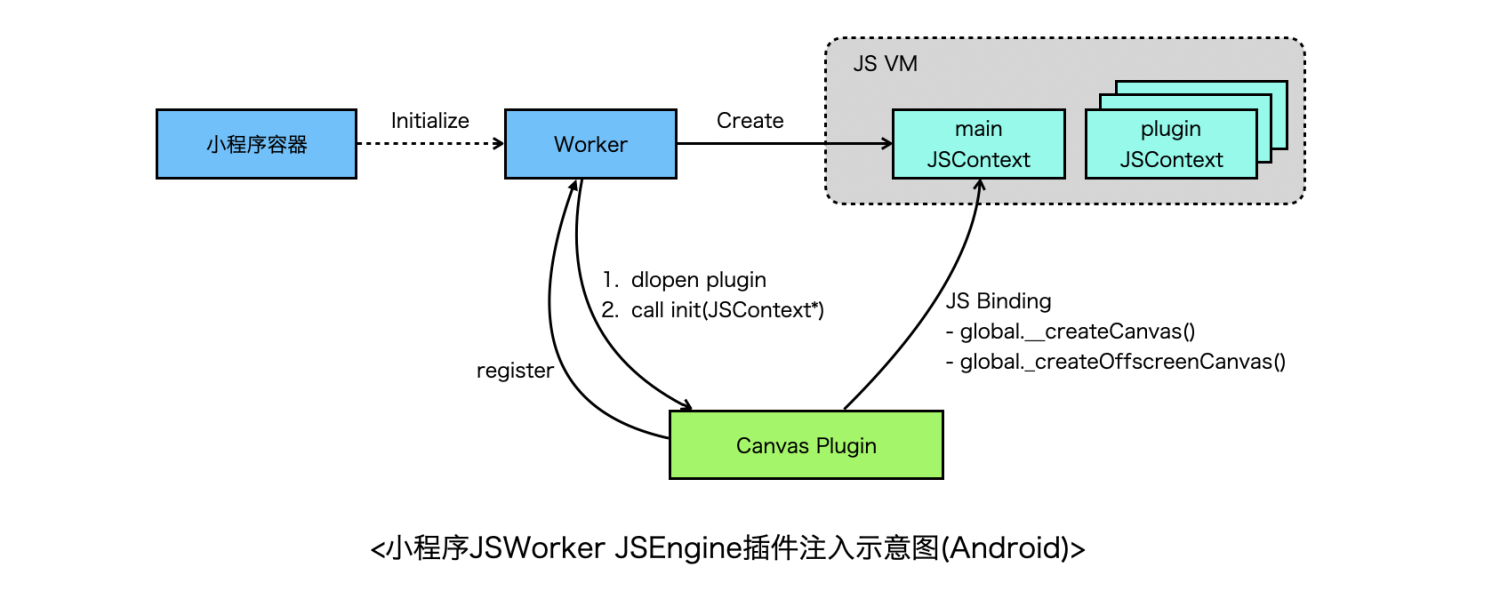
以小程序环境为例,小程序容器初始化时,会分别创建Render和Worker,Render负责界面渲染,Worker负责执行业务逻辑,拥有独立JSContext,Canvas提供了createCanvas()和createOffscreenCanvas() 全局函数需要绑定到该JSContext的GlobalObject上,因此Worker需要有一个时机通知canvas注入API,从小程序视角来看,Worker依赖Canvas显然不合理,因此小程序提供了插件机制,每个插件都是一个动态库,Canvas作为插件先注册到Worker,随后Worker创建之后会扫描一遍插件,依次dlopen每个插件并执行插件的初始化函数,将JSContext作为参数传给插件,这样插件就可以向JSContext中绑定API了。
![]()
关于JSEngine和Binding有两个需要注意的点(以V8为例):
- 关于线程安全。JSContext通常设计为非线程安全的,需要注意不要在非JS线程中访问JS资源。其次,在V8中一个线程可能有多个JSContext,需要使用v8::Context::Scope切换正确的JSContext;
- 关于Binding对象的生命周期。众所周知,C与JS语言内存管理方式不一样,C需要开发者手动管理内存,JS由虚拟机管理。对于C++ Binding的JS对象的生命周期理论上需要跟普通JS对象一致,因此需要有一种机制,当JS对象被GC回收时,需要通知到C++ Binding对象,以便执行相应的析构函数释放内存。事实上,JS引擎通常会提供让一个JS对象脱离/回归GC管理的机制,且JS对象的生命周期均有钩子函数可以进行监听。V8中有Handle(句柄)的概念,Handle分为LocalHandle、PersistentHandle、Weak PersistentHandle。LocalHandle在栈上分配,由HandleScope控制其作用域,超出作用域即被标记为可释放,PersistentHandle在堆上分配,生命周期长,通常需要开发者显式通过PersistentHandle#Reset的方式释放对象。通过SetWeak函数可以让一个PersistentHandle转为一个Weak PersistentHandle,当没有其他引用指向Weak句柄时就会触发回调,开发者可以在回调中释放内存。
最后再讨论下Binding代码如何跨JSEngine的问题。
当前主流的JSEngine有V8、JavaScriptCore、QuickJS等,如果需要更换JSEngine的话,Binding代码需要重写,成本有点高(Canvas接口非常多),因此理论上可以再封装一个抽象层,屏蔽不同引擎的差异,对外提供一致接口,基于抽象层编写一次Binding代码,就可以适配到多个JSEngine(使用IDL生成代码是另外一条路),目前我们使用了UC团队提供的JSI SDK适配多JS引擎。
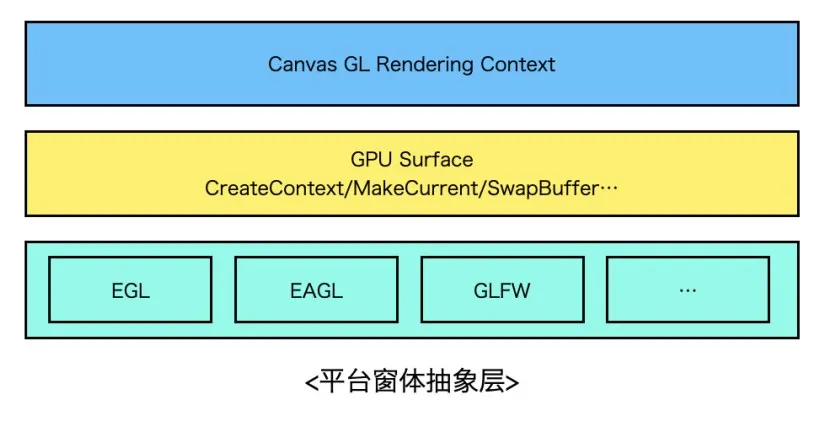
平台窗体抽象层设计
要想做到跨平台,就需要设计一个抽象的平台胶水层,胶水层的职责是对下屏蔽各个平台间的实现差异,对上为Canvas提供统一的接口操作Surface,封装MakeCurrent、SwapBuffer等行为。实现上可以借鉴Flutter Engine,Flutter Engine的Shell模块对GL胶水层做了较好的封装,可以无缝接入到Android、iOS等主流平台,扩展到新平台比如鸿蒙OS也不在话下。
当设计好GL胶水层接口后,分平台进行实现即可。以Android为例,如果想创建一个GL上下文并绘制到屏幕上,必须通过EGL绑定平台窗体环境,即Surface或者是ANativeWindow对象,而能够创建Surface的View只有SurfaceView和TextureView(如果是一个全屏游戏没有其他Native View的话,还可以考虑直接使用NativeActivity,这里先不考虑这种情况),应该如何选择?这里可以从渲染原理上分析下两者的差异再分场景进行决策。
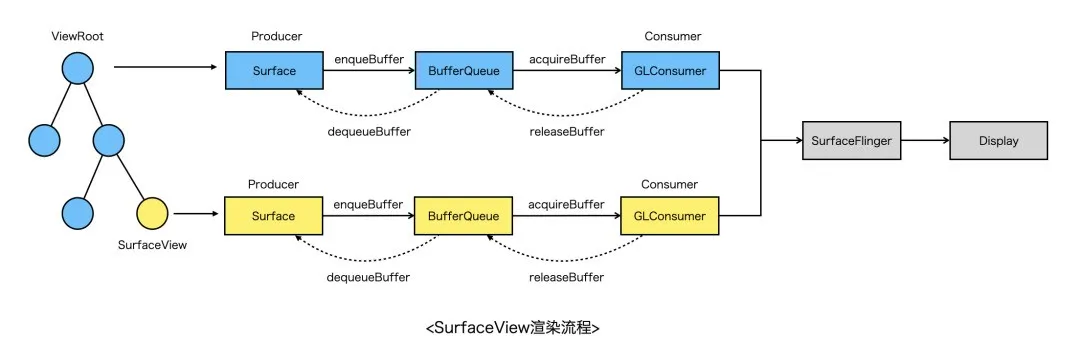
先看SurfaceView的渲染流程,简单来说分为如下几个步骤(硬件加速场景):
- 通过SurfaceView申请的Surface创建EGL环境;
- Surface通过dequeueBuffer向SurfaceFlinger请求一块GraphicBuffer(可理解为一块内存,用于存储绘图数据),随后所有绘制内容都会写到这块Buffer上;
- 当调用EGL swapBuffer之后,会将GraphicBuffer入队到BufferQueue;
- SurfaceFlinger在下一个VSYNC信号到来时,取GraphicBuffer,进行合成上屏;
对比SurfaceView,TextureView的渲染流程更长一些,主要经历以下关键阶段:
- 通过TextureView绑定的SurfaceTexture创建EGL环境;
- 生产端(Surface)通过dequeueBuffer从SurfaceTexture管理的BufferQueue中获得一块GraphicBuffer,后续所有绘制内容都会写到这块Buffer上;
- 当调用EGL swapBuffer之后,会将GraphicBuffer入队到SurfaceTexture内部的BufferQueue;
- 随后TextureView触发frameAvailable,通知系统进行重绘(view#invalidate);
- 系统在下次VSYNC信号到来的时候进行重绘,在UI线程生成DisplayList,然后驱动渲染线程进行真正渲染;
- 渲染线程会将步骤2中的GraphicBuffer作为一张特殊的纹理(GL_TEXTURE_EXTERNAL_OES)上传,与View Hierarchy上其他视图一起通过SurfaceFlinger进行合成;
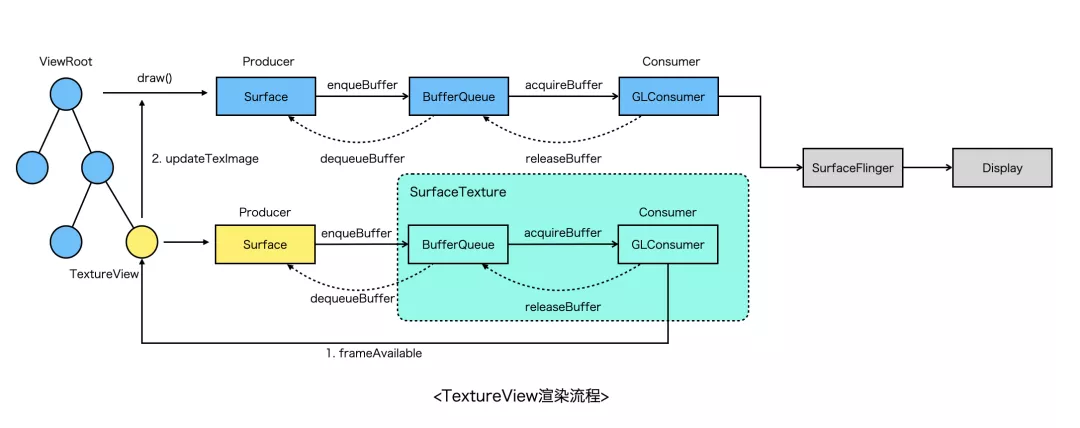
由以上两者的渲染流程对比可发现,SurfaceView的优势是渲染链路短、性能好,但是相比普通的View,没法支持Transform动画,通常全屏的游戏、视频播放器优先选择SurfaceView。而TextureView则弥补了SurfaceView的缺陷,它跟普通的View完全兼容,同样会走HWUI渲染,不过缺陷是内存占用比SurfaceView高,渲染需要在多个线程之间同步整体性能不如SurfaceView。
具体如何选择需要分场景来看,以我们为例,我们这边同时支持在SurfaceView和TextureView中渲染,但是由于目前主要服务于淘宝小程序互动业务,而在小程序容器中,需要通过UC提供的WebView同层渲染技术将Canvas嵌入到WebView中,由于业务上需要同时支持全屏和非全屏互动,且需要支持各种CSS效果,因此只能选择EmbedSurface模式,而EmbedSurface不支持SurfaceView,因此我们选择的是TextureView。
渲染管线
Canvas渲染引擎的核心当然是渲染了,上层的互动业务的性能表现,很大程度取决于Canvas的渲染管线设计是否足够优秀。这一部分会分别讨论Canvas2D/WebGL的渲染管线技术选型及具体的方案设计。
▐ Canvas2D Rendering Context
基础能力
从Canvas2D标准来看,引擎需要提供的原子能力如下:
- 路径绘制,包括直线、矩形、贝塞尔曲线等等;
- 路径填充、描边、裁剪、混合,样式与颜色设置等;
- 图元变换(transform)操作;
- 文本与位图渲染等。
软件渲染 VS 硬件渲染
软件渲染指的是使用CPU渲染图形,而硬件渲染则是利用GPU。使用GPU的优势一方面是可以降低CPU的使用率,另外GPU的特性(擅长并行计算、浮点数运算等)也使其性能通常会更好。但是GPU在发展的过程中,更多关注的是三维图形的运算,二维矢量图形的渲染似乎关注的较少,因此可以看到像freetype、cairo、skia等早期主要都是使用CPU渲染,虽然khronos组织推出了OpenVG标准,但是也并没有推广开来。目前主流的移动设备都自带GPU,因此对于Canvas2D的技术选型来说,我们更倾向于使用硬件加速的引擎,具体分析可以接着往下看。
技术选型
Canvas2D的实现成本颇高,从零开始写也不太现实,好在社区中有很多关于Canvas 2D矢量绘制的库,这里仅列举了一部分比较有影响力的,主要从backend、成熟度、移植成本等角度进行评判,详细如下表所示。
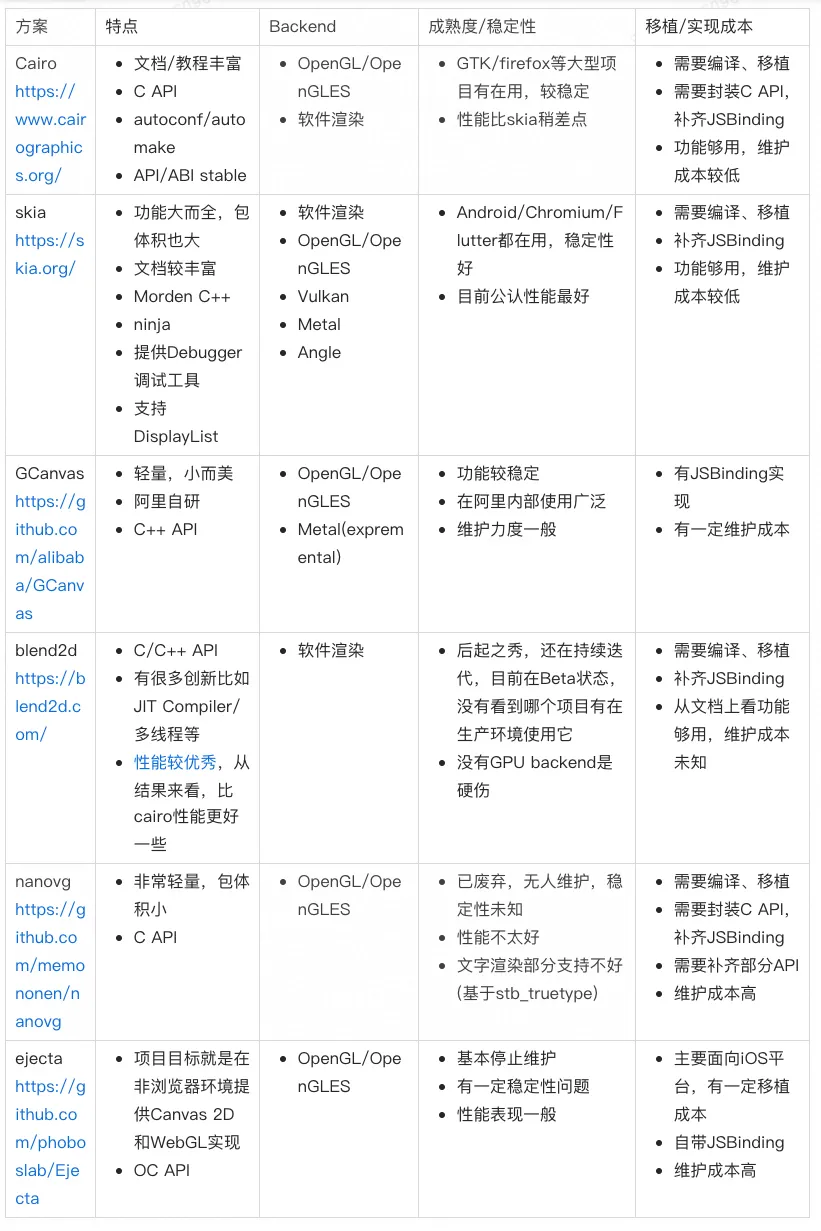
Cairo和Skia是老牌的2D矢量图形渲染引擎了,成熟度和稳定性都很高,且同时支持软件与硬件渲染(cairo的硬件渲染支持比较晚),性能上通常skia占优(也看具体case),不过体积大的多。nanovg和GCanvas以小而美著称,性能上GCanvas更优秀一点,nanovg需要经过特别的定制与调优,文字渲染也不尽如人意。Blend2D是一个后起之秀,通过引入并发渲染、JIT编译等特性宣称比Caico性能更优,不过目前还在beta阶段,且硬伤是只支持软件渲染,没办法利用GPU硬件能力。最后ejecta项目最早是为了在非浏览器环境支持W3C Canvas标准,有OpenGLES backend,自带JSBinding实现,不过可惜的是现在已无人维护,性能表现也比较一般。
我认为技术选型没有最好的方案,只有最适合团队的方案,从实现角度来看,以上列举的方案均可以达到目标,但是没有银弹,选择不同的方案对技术同学的要求、产品的维护成本、性能&稳定性、扩展性等均会产生深远的影响。以我们团队为例,业务形态上看主要服务于淘系互动小程序业务,面向的是淘宝开放平台上的商家、ISV开发者等, 我们对于Canvas渲染引擎最主要的诉求是跨平台渲染一致性、性能、稳定性,因此nanovg、blend2d、ejecta不满足需求。从团队资源的角度看,我们更倾向于使用开箱即用、维护成本低的方案,ejecta、GCanvas不满足需求。最后从组织架构上看,我们团队主要负责手淘跨平台相关产品,其中包括Flutter,而Flutter自带了skia,它同时满足开箱即用、高性能&高可用等特点,而且由于Chromium同样使用了skia,因此渲染一致性也得到了保证,所以复用skia对于我们来说是相对比较优的选择,但与此同时我们的包大小也增大了很多,未来需要持续优化包大小。
渲染管线细节
这里主要介绍下基于Skia的Canvas 2D渲染流程。JSBinding代码的实现较简单,可以参考chromium Canvas 2D的实现,这里就不展开了。
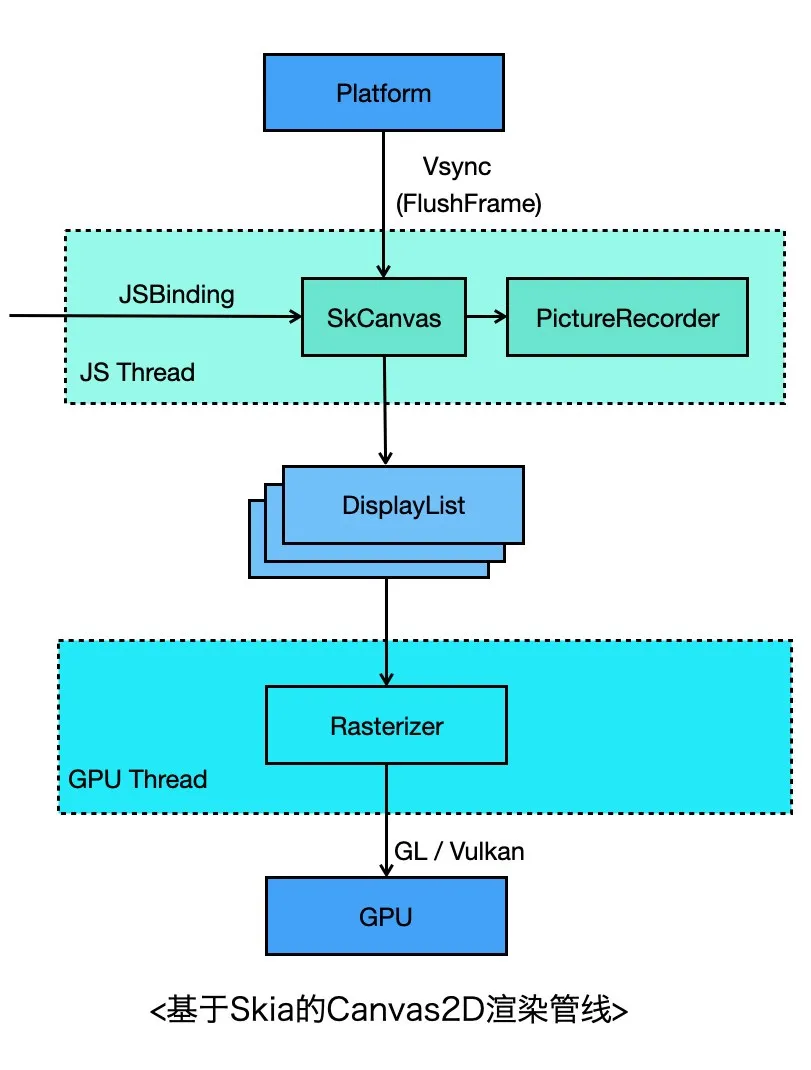
看下渲染的流程,关键步骤如下,其中4~6步与当前Flutter Engine基本保持一致:
- 开发者创建Canvas对象,并通过 Canvas.getContext('2d') 获取2D上下文;
- 通过2D上下文调用Canvas Binding API,内部实际上通过SkCanvas调用Skia的绘图API,不过此时并没有绘制,而是将绘图命令记录下来;
- 当平台层收到Vsync信号时,会调度到JS线程通知到Canvas;
- Canvas收到信号后,停止记录命令,生成SkPicture对象(其实就是个DisplayList),封装成PictureLayer,添加到LayerTree,发送到GPU线程;
- GPU线程Rasterizer模块收到LayerTree之后,会拿到Picture对象,交给当前Window Surface关联的SkCanvas;
- 这个SkCanvas先通过Picture回放渲染命令,再根据当前backend选择vulkan、GL或者metal图形API将渲染指令提交到GPU。
文字渲染
文字渲染其实非常复杂,这里仅作简要介绍。
目前字体的事实标准是OpenType和TrueType,它们通过使用贝塞尔曲线的方式定义字体的形状,这样可以保证字体与分辨率无关,可以输出任意大小的文字而不会变形或者模糊。
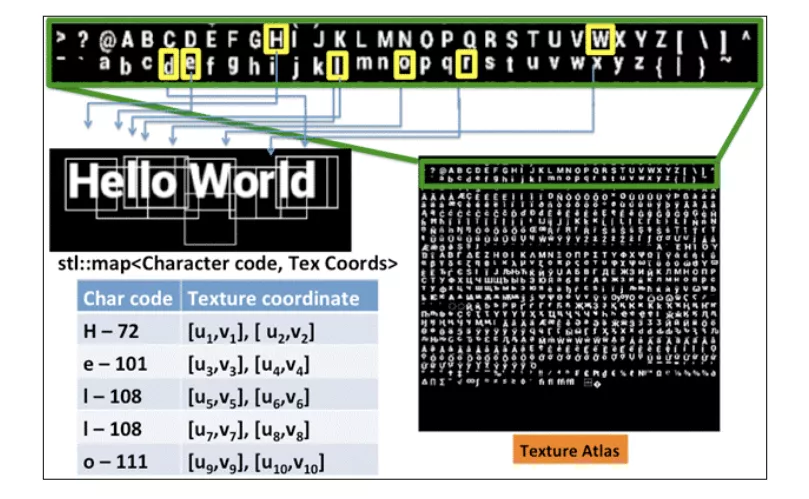
众所周知,OpenGL并没有提供直接的方式用于绘制文字,最容易想到的方式是先在CPU上加载字体文件,光栅化到内存,然后作为GL纹理上传到GPU,目前业界用的最广泛的是 Freetype 库,它可以用来加载字体文件、处理字形,生成光栅化的位图数据。如果每个文字对应一张纹理显然代价非常高,主流的做法是使用 texture atlas 的方式将所有可能用到的文字全部写到一张纹理上,进行缓存,然后根据uv坐标选择正确的文字,有点类似雪碧图。
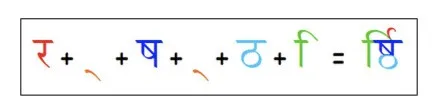
以上还只是文字的渲染,当涉及到多语言、国际化时,情况会变得更加复杂,比如阿拉伯语、印度语中连字(Ligatures)的处理,LTR/RTL布局的处理等,Harfbuzz 库就是专门用来干这个的,可以开箱即用。
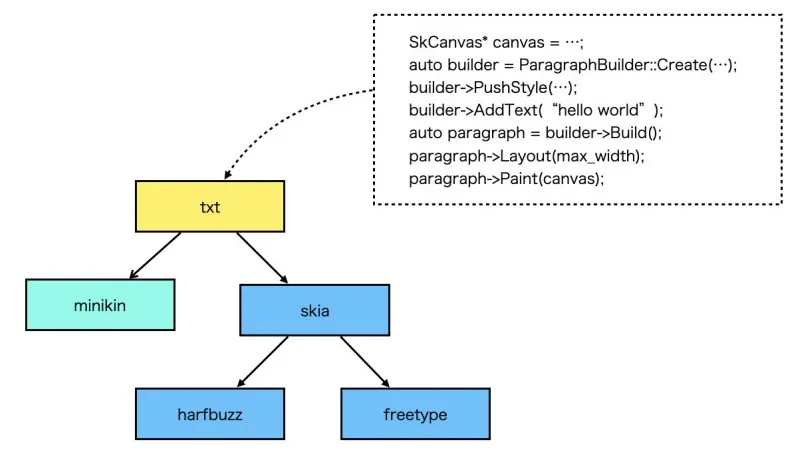
从Canvas2D的文字API来看,只需要提供文本测量和基本的渲染的能力即可,使用OpenGL+Freetype+Harfbuzz通常就够用了,但是如果是一个GUI应用如Android、Flutter,那么还需要处理断句断行、排版、emoji、字体库管理等逻辑,Android提供了一个minikin库就是用来干这个的,Flutter中的txt模块二次封装了minikin,提供了更友好的API。目前我们的Canvas引擎的文字渲染模块跟Flutter保持一致,直接复用libtxt,使用起来比较简单。
上面涉及到的一些库链接如下:
- Freetype: https://www.freetype.org/
- Harfbuzz: https://harfbuzz.github.io/
- minikin: https://android.googlesource.com/platform/frameworks/minikin/
- flutter txt:
https://github.com/flutter/engine/blob/master/third_party/txt
位图渲染
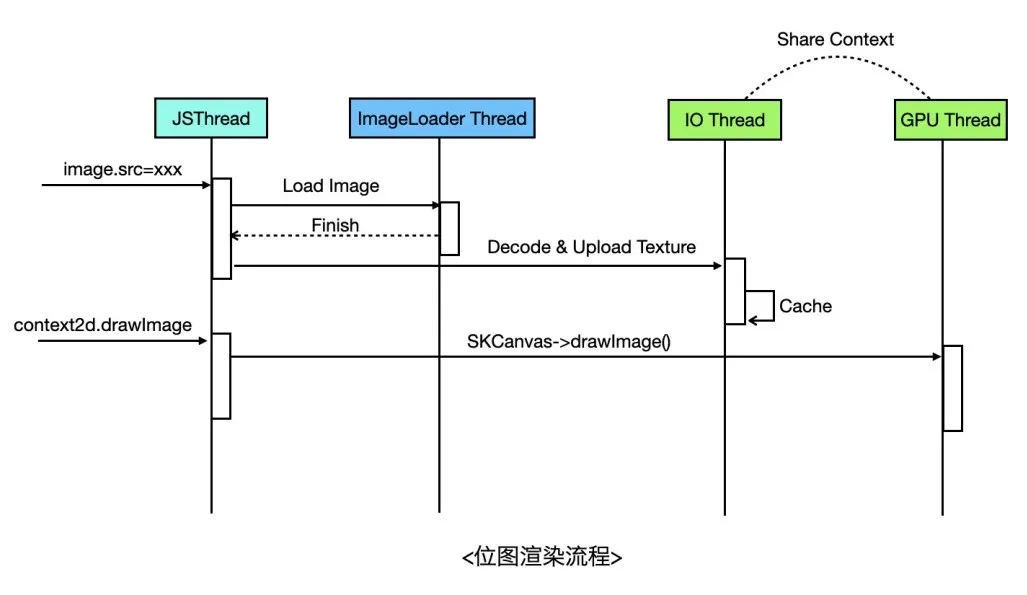
位图渲染的基本流程是下载图片 -> 图片解码 -> 获得位图像素数据 -> 作为纹理上传GPU -> 渲染位图,拿到像素数据后,就可以上传到GPU作为一张纹理进行渲染。不过由于上传像素数据也是个耗时过程,可以放到独立的线程做,然后通过Share GLContext的方式使用纹理,这也是Flutter目前的做法,Flutter会使用独立的IO线程用于异步上传纹理,通过Share Context与GPU线程共享纹理,与Flutter不一样的是,我们的图片下载和解码直接代理给原生的图片库来做。
▐ WebGL Rendering Context
WebGL实现比2D要简单的多,因为WebGL的API基本与OpenGLES一一对应,只需要对OpenGLES API简单进行封装即可。这里不再介绍OpenGL本身的渲染管线,而主要关注下WebGL Binding层的设计,从技术实现上主要分为单线程模型和双线程模型。
单线程模型即直接在JS线程发起GL调用,这种方式调用链路最短,在一般场景性能不会有大的问题。但是由于WebGL的API调用与业务逻辑的执行都在JS线程,而某些复杂场景每帧会调用大量的WebGL API,这可能会导致JS线程阻塞。

通过profile可以发现,这个场景JS线程的阻塞可能并不在GPU,而是在CPU,原因是JS引擎Binding调用本身的性能损耗也很可观,有一种优化方案是引入Command Buffer优化JSBinding链路损耗,如下图所示。
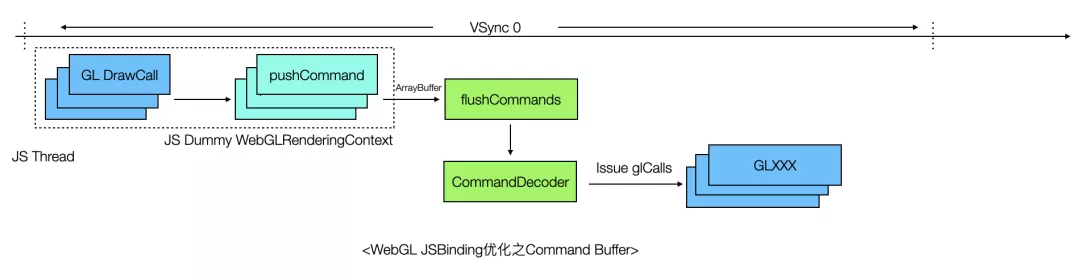
这个方案的思路是这样的,JS侧封装一个虚拟的 WebGLRenderingContext 对象,API与W3C标准一致,但是其实现并不调用Native侧的JSBinding接口,而是按照指定规则对WebGL Call进行编码,存储到ArrayBuffer中,然后在特定时机(如收到VSync信号或者时执行到同步API时)通过一个Binding接口(上图flushCommands)将ArrayBuffer一次性传到Native侧,之后Native对ArrayBuffer中的指令查表、解析,最后执行渲染,这样做可以减少JSBinding的调用频率,假设ArrayBuffer中存储了N条同步指令,那么只需要执行1次Binding调用,减少了(N-1)次Binding调用的耗时,从而提升了整体性能。
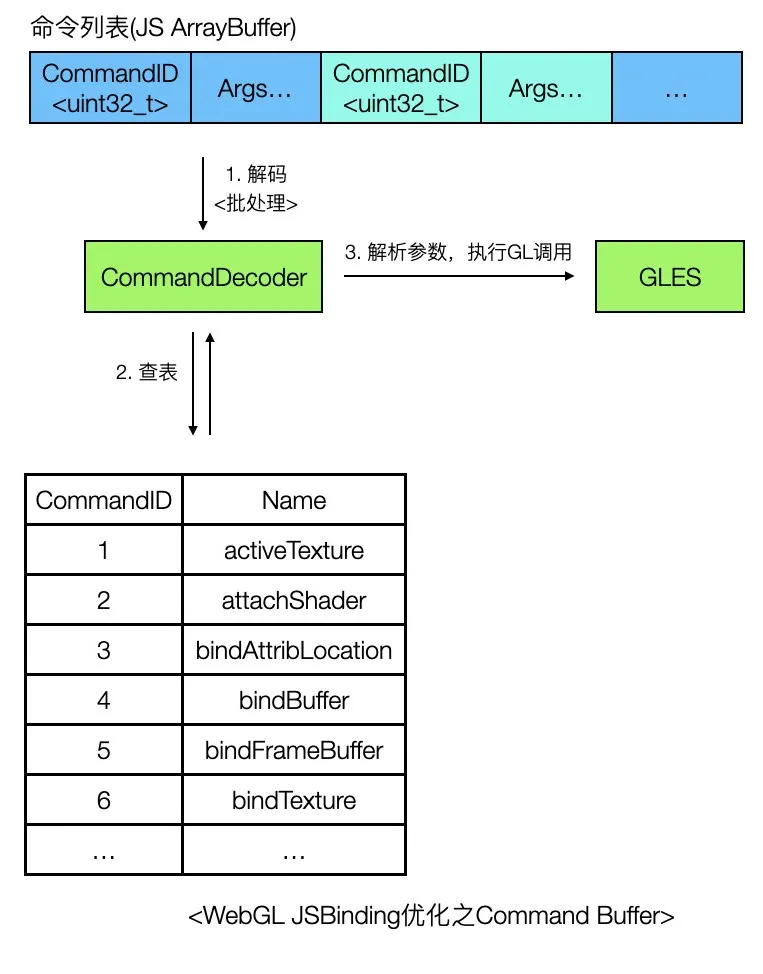
双线程模型指的是将GL调用转移到独立的渲染线程执行,解放JS线程的压力。具体的做法可以参考chromium GPU Command Buffer(注意这里的Command Buffer与上面提到的解决的并不是同一个问题,不要混淆),思路是这样的,JS线程收到Binding调用后,并不直接提交,而是先encode到Command Buffer(通常使用Ring buffer数据结构)缓存起来,随后在渲染线程中访问CommandBuffer,进行Decode,调用真正的GL命令,双线程模型实现要复杂的多,需要考虑Lock Free&WaitFree、同步、参数拷贝等问题,写的不好可能性能还不如单线程模型。
最后再提一句,在chromium中,不仅实现了多线程的WebGL渲染模型,还支持了多进程Command Buffer的模型,使用多进程模型可以有效屏蔽各种硬件兼容性问题,带来更好的稳定性。
▐ 离屏渲染
离屏Canvas在Web中还是个实验特性,不过因为其实用性,目前主流的小游戏/小程序容器基本都实现了。使用到离屏Canvas的主要是2D的 drawImage 接口以及WebGL的 texImage2D/texSubImage2D 接口,WebGL通常会使用离屏Canvas渲染文本或者做一些游戏场景的预热等等。
离屏渲染通常会使用PBuffer或者FBO来实现:
- PBuffer: 需要通过PBuffer创建新的GL Context,每次渲染都需要切换GL上下文;
- FBO: FBO是OpenGL提供的能力,通过 glGenFramebuffers 创建FBO,可以绑定并渲染到纹理,并且不需要切换GL上下文,性能通常会更好些(没有做过测试,严格来说也不一定,因为目前移动端GPU主要采用TBR架构,切换FrameBuffer可能会造成Tile Cache失效,导致性能下降)。
除了上面两种方案之外,Android上还可以通过SurfaceTexture(本质上是EGLImage)实现离屏渲染,不过这是一种特殊的纹理类型,只能绑到GL_TEXTURE_EXTERNAL_OES上。特别地,对于2D来说,还可以通过CPU软件渲染来间接实现离屏渲染。
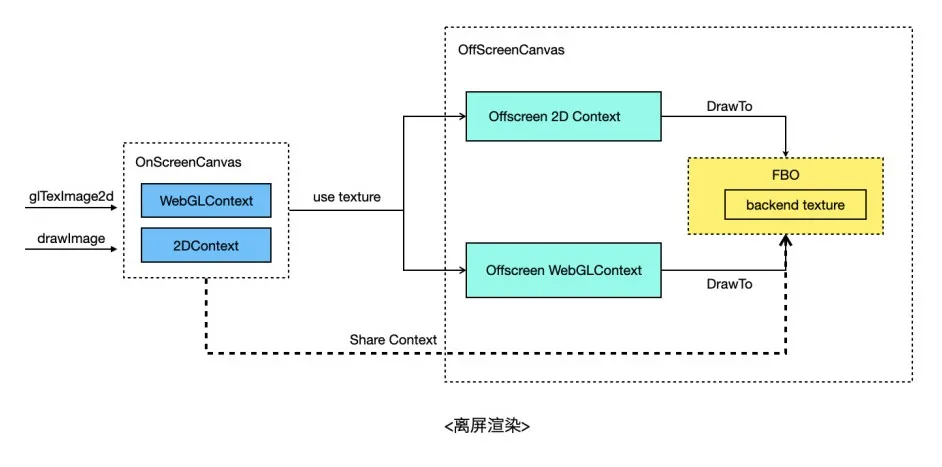
离屏渲染中比较影响性能的地方是上传离屏Canvas数据到在屏Canvas,如果先readPixels再upload性能会比较差。解决方案是将离屏Canvas渲染到纹理,再通过OpenGL shareContext的方式与在屏Canvas共享纹理。这样,对于在屏Canvas来说就可以直接复用这个纹理了,具体点,对于在屏2D Context的drawImage来说,可以基于该纹理创建texture backend SkImage,然后作为图片上传。对于在屏WebGL Context的texImage2D来说,有几种方式,一种方式提供非标API,调用该API将直接绑定离屏Canvas所对应的纹理,开发者不用自己再创建纹理。另一种方式是texImage2D时,通过FBO拷贝离屏纹理到开发者当前绑定的纹理上。还有一种方式是在texImage2D时,先删除用户当前绑定的纹理,然后再绑定到离屏Canvas所对应的纹理,这种方案有一定使用风险,因为被删除的纹理可能还会被开发者用到。
帧同步机制
所谓帧同步指的是游戏渲染循环与操作系统的显示子系统(在Android平台即为SurfaceFlinger)和底层硬件之间的同步。众所周知,在GPU加速模式下,我们在屏幕上看到的游戏或者动画需要先在CPU上完成游戏逻辑的运算,然后生成一系列渲染指令,再交由GPU进行渲染,GPU的渲染结果写入FrameBuffer,最终会由显示设备刷新到屏幕。
显示设备的刷新频率(即刷新率)通常是固定的,移动设备主流的刷新频率是60HZ,也即每秒刷新60次,但是GPU渲染的速度却是不固定的,它取决于绘制帧的复杂程度。这会导致两个问题,一是帧率不稳定,用户体验差;二是当GPU渲染频率高于刷新频率时,会导致丢帧、抖动或者屏幕tearing的现象。
解决这个问题的方案是引入双缓冲和垂直同步(VSYNC),双缓冲指的是准备两块图形缓冲区,BackBuffer给GPU用于渲染,FrontBuffer由显示设备进行显示,这样可以提高系统的吞吐量,提高帧率并减少丢帧的情况。垂直同步是为了协调绘制的步调与屏幕刷新的步调一致,GPU必须等到屏幕完整刷新上一帧之后再进行渲染,因为GPU渲染频率高于刷新率通常是没有意义的。在PC机上早期的垂直同步是用软件模拟的,不过NVIDA和AMD后来分别出了G-SYNC和FreeSync,需要各家的硬件配合。
而Android平台上是在Android4.x引入了VSYNC机制,在之后的版本还引入了RenderThread、TripleBuffer(三缓冲)等关键特性,极大提高了Android应用的流畅度。
以下是Android平台的渲染模型,一次完整的渲染(GPU加速下)大致会经过如下几个阶段:
- HWC产生VSYNC事件,分别发给SurfaceFlinger合成进程与App进程;
- App UI线程(通过Choreographer)收到VSYNC信号后,处理用户输入(input)、动画、视图更新等事件,然后将绘图指令更新到DisplayList中,随后驱动渲染线程执行绘制;
- 渲染线程解析DisplayList,调用hwui/skia绘图模块将渲染指令发给GPU;
- GPU进行绘制,绘制结果写入图形缓冲区(GraphicBuffer);
- SurfaceFlinger进程收到VSYNC信号,取图形缓存区内容进行合成;
- 显示设备刷新,屏幕最终显示相应画面;
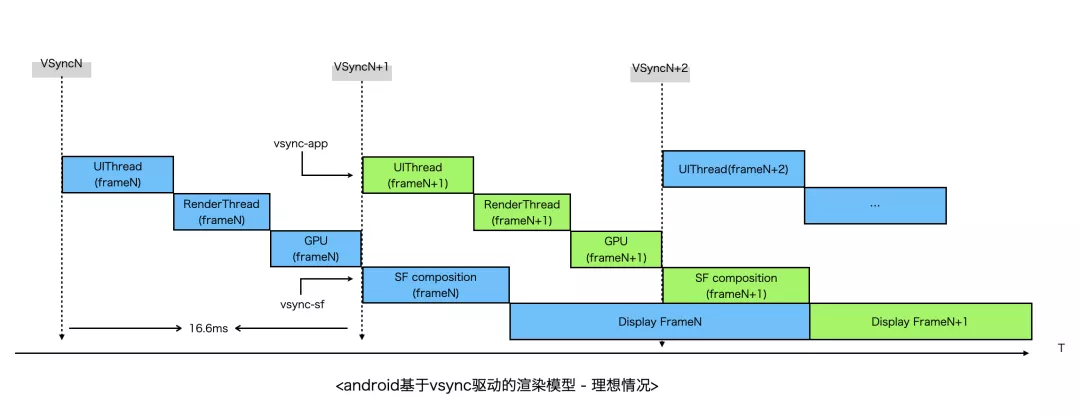
值得注意的是,默认情况下App与SurfaceFlinger同时收到VSYNC信号,App生产第N帧,而SurfaceFlinger合成第N-1帧画面,也即App第N帧产生的数据在第N+1次VSYNC到来时才会显示到屏幕。VSYNC+双缓冲的模型保证了帧率的稳定,但是会导致输出延迟,且并不能解决卡顿、丢帧等问题,当UI线程有耗时操作、渲染场景过于复杂、App内存占用高等等场景就会导致丢帧。丢帧从系统层面上看原因主要是由于CPU/GPU不能在规定的时间内生产帧数据导致SurfaceFlinger只能使用前一帧的数据去合成,Android通过引入VSYNC offset、Triple Buffer等策略进行了一定程度的优化,不过要想帧率流畅主要还是得靠开发者分场景去做针对性的优化。
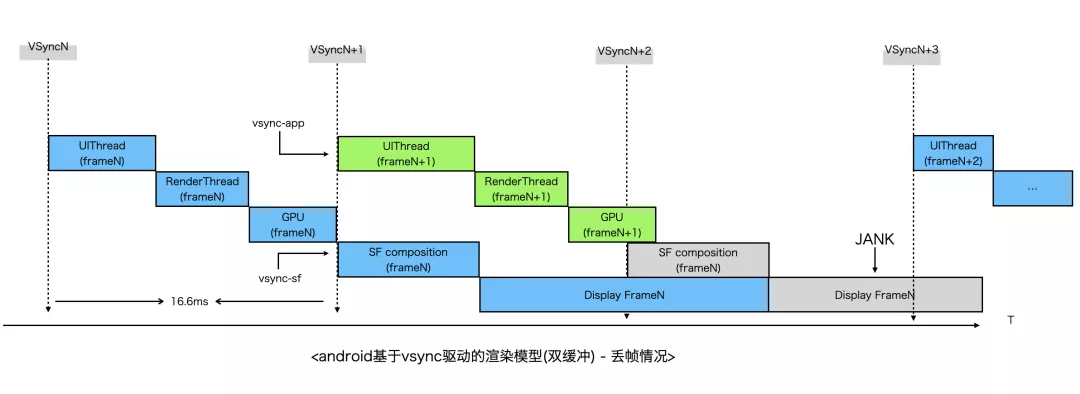
与原生的渲染流程类似,Canvas渲染引擎的绘制流程也是由VSYNC驱动的,在Android平台上可以通过 Choreographer注册VSYNC Callback,当VSYNC信号到来时,就可以执行一次Canvas 2D/WebGL的绘制。以WebGL单线程模型为例,一次绘制过程如下:
- 在JS线程,游戏引擎调用Canvas WebGLContext执行WebGL Binding调用;
- 在Android UI线程,Canvas收到平台VSYNC信号;
- 通过消息队列调度到JS线程,在JS线程遍历Canvas实例,找到所有WebGL渲染上下文;
- 对每个需要执行渲染(dirty)的WebGL上下文执行SwapBuffer;
这里其实还涉及到一个问题,如果当前Canvas渲染的内容未发生变化,是否还需要监听VSYNC信号? 这就是所谓的OnDemand Rendering和Continuously Rendering模型。在 OnDemand 模型下,应用层调用了Canvas API就会标记状态为dirty同时向系统请求VSYNC,下一次收到VSYNC callback时执行绘制,而在Continuously 模型下,会一直向系统请求下一次VSYNC,在VSYNC Callback时再去判断是否需要绘制。理论上OnDemand模型更为合理,避免了不必要的通信,功耗更低, 不过Continuously模型实现上更为简单。Android与Flutter均采用了OnDemand模型,而我们则同时支持两种模式。
以上仅仅考虑了Canvas自身的渲染流程,在上文窗体环境搭建中,Android平台我们最终选择了TextureView作为Canvas的Render Target,那么在引入了TextureView之后,从操作系统的角度看,宏观的渲染流程又是怎样的呢? 我画了这张图,为简单起见,这里以TextureView Thread代表Canvas的渲染线程。
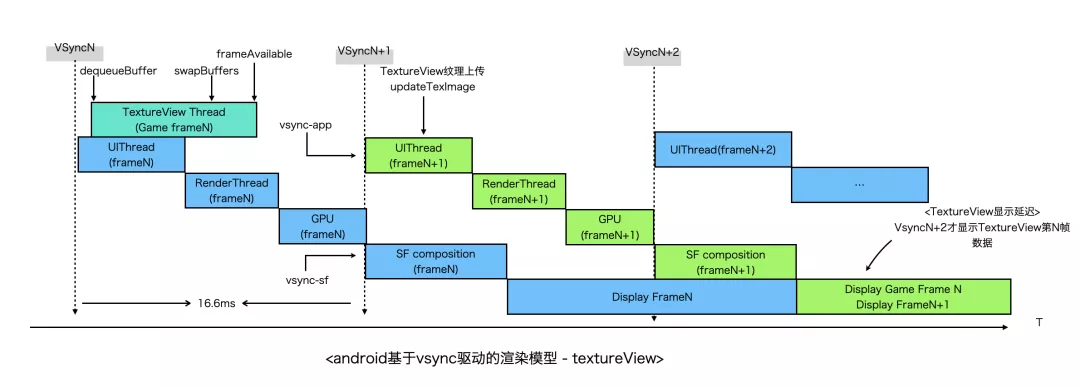
TextureView基于SurfaceTexture,由于没有独立Surface,渲染合成依赖于Android HWUI,TextureView生产完一帧的数据后,还需触发一次view invalidate,再走一次ViewRootImpl#doTraversal流程,因此整体流水线更长,从图上可知,在没有丢帧的情况下,显示也会延迟,第N帧的绘制在第N+2帧才会显示到屏幕上。
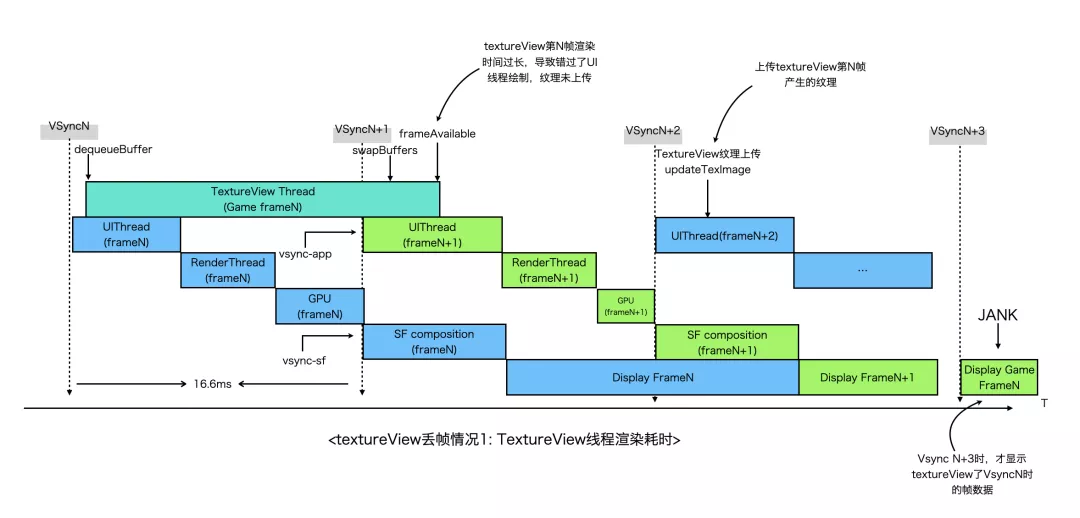
同时,TextureView下卡顿、丢帧的情况也更为复杂,有时即使FPS很高但是依然感觉卡顿,下面是常见的两种丢帧情况。
第一种丢帧情况是第N帧TextureView线程渲染超时,导致错过了N+1帧UI线程的绘制。
第二种丢帧情况是UI线程卡顿而TextureView线程渲染较快,导致第N+1帧时UI线程上传的是TextureView第N+1帧的纹理,而第N帧的纹理被忽略掉了。
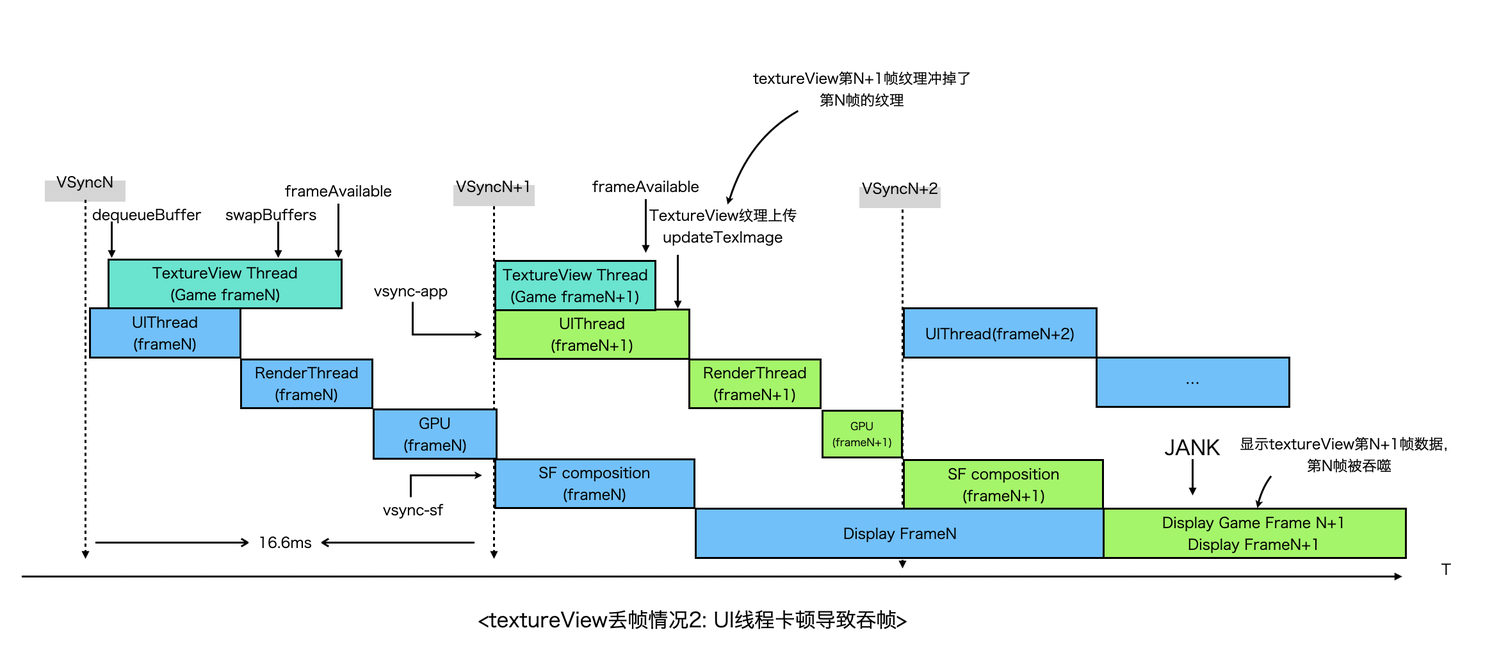
以上可见,在游戏等重渲染场景,SurfaceView是比TextureView更好的选择,另外,分析卡顿往往需要对整个系统的底层机制有较深了解才能顺利解决问题,这对开发者也提出了更高的要求。
调试
最后讨论下调试的话题。对于Canvas渲染引擎,传统的调试方法如日志、断点调试、systrace对于问题诊断依然十分有用。不过由于引擎会用到Java/OC/C++/JS等语言,调试的链路大大延长,开发者需要根据经验或者对问题的分析进行针对性的调试,有一定的难度。除了使用上面几种方式调试之外,还可以使用一些GPU调试工具辅助,下面简要介绍下。
▐ Gapid(Graphic API Debugger)
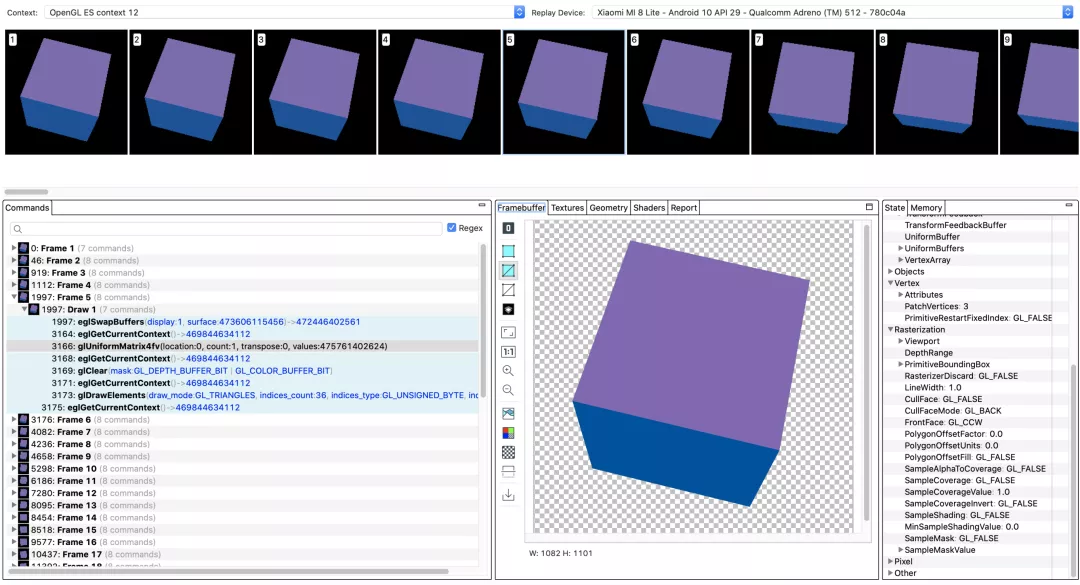
Gapid是Android平台提供的GPU调试工具,功能十分强大,它可以Inspect 任意Android应用的OpenGLES/Vulkan调用,无论是系统的GL上下文(如hwui/skia等)还是应用自己创建的GL上下文都能追踪到,细化到每一帧的话,可以查看该帧所有的Draw Call、GL状态机的运行状态、FrameBuffer内容、创建的Texture、Shader、Program等等。通过这个工具除了可以验证渲染正确性之外,还可以辅助性能调优(如频繁的上下文切换、大纹理的分配等等)、诊断可能发生的GPU内存泄露等等。
▐ Snapdragon Profiler
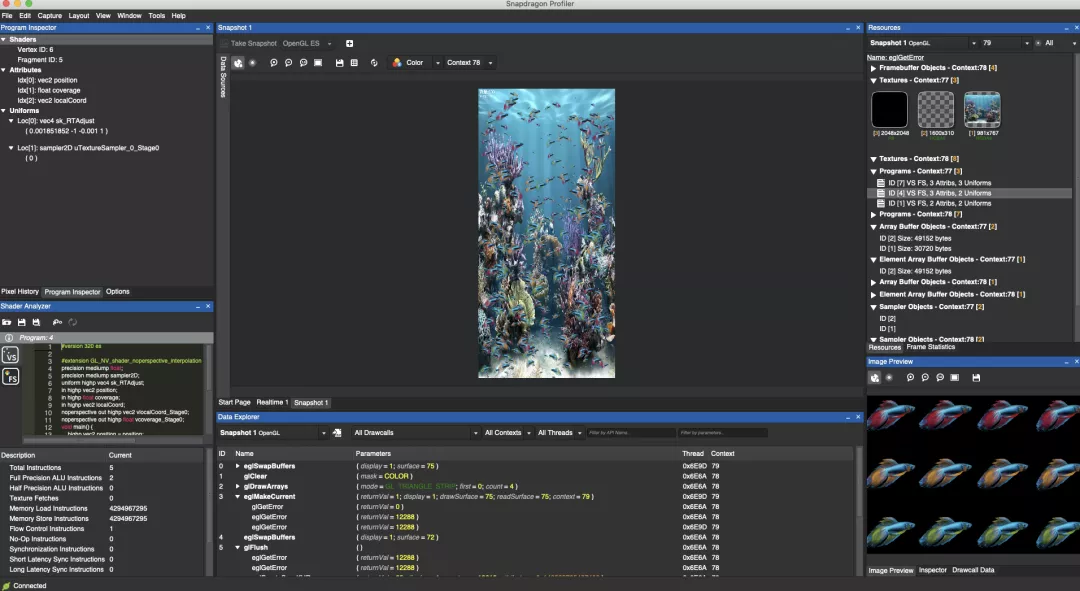
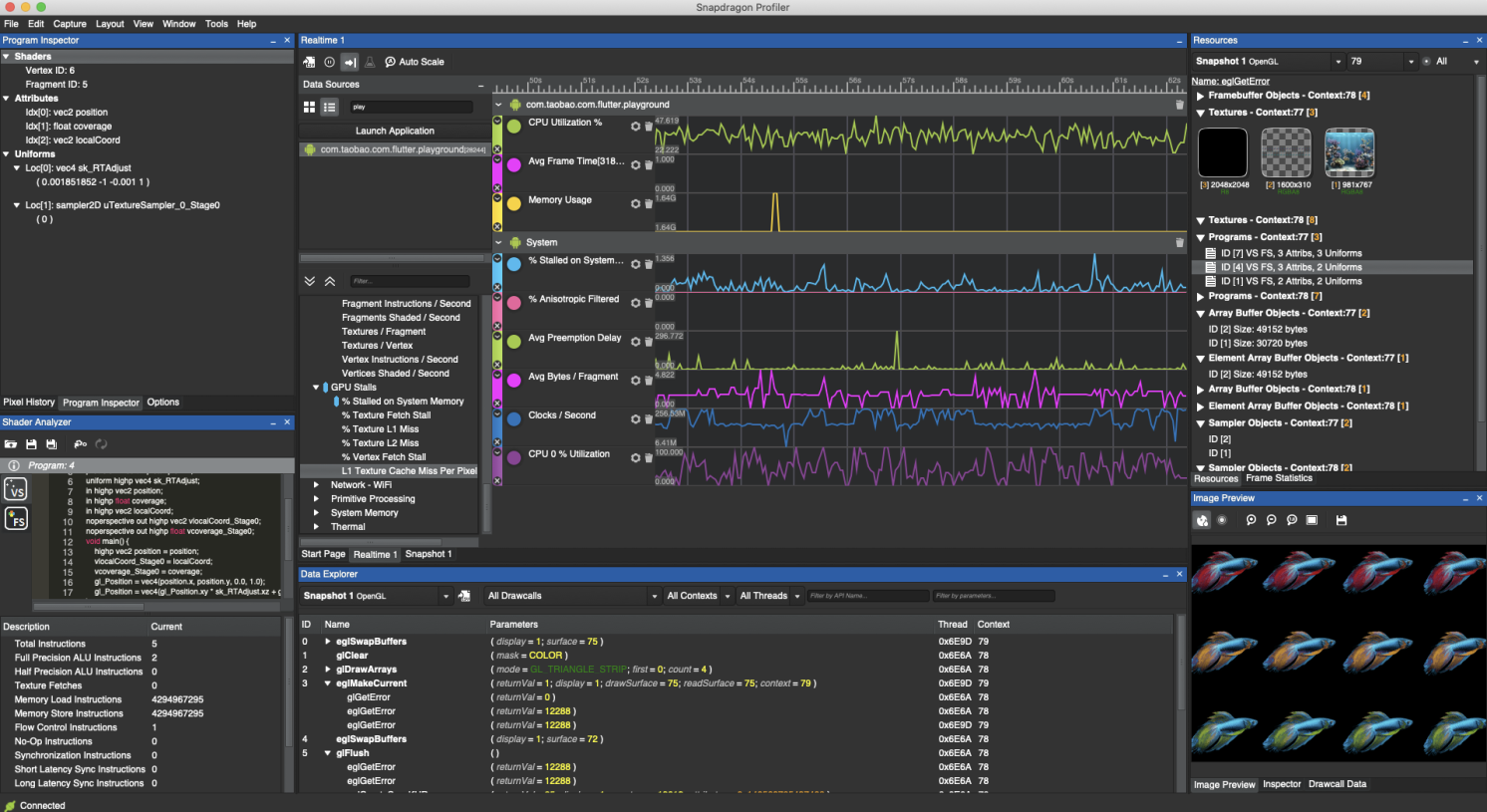
Snapdragon Profiler是高通开发一款GPU调试工具,使用了高通芯片的设备应该都能使用。这个工具也提供了类似的GPU Profiler的工具,可以抓帧分析,不过个人觉得没有gapid好用。除此之外,snapdragon还提供了实时性能分析的功能,可以查看CPU、GPU、网络、FPS、电量等等全方位的性能数据,比Android Studio更强大。有兴趣的同学可以研究下。
总结
以上基本讲清楚了如何实现一个跨平台Canvas引擎,然而这还只是第一步,还有更多的挑战在前面,比如Canvas与容器层的研发链路、生产链路如何协同? 如何保障线上功能的稳定性?如何管控内存使用?如何优化启动速度等等。另外,对于复杂游戏来说,游戏引擎的使用必不可少,游戏引擎使用Canvas作为渲染接口并不是性能最佳的方案,如果可以将游戏引擎中的通用逻辑下沉,提供更高阶API,势必会对性能带来更大的提升。





