

本文旨在分享正负反馈序列建模与多目标优化在淘宝直播排序上的实践经验。
背景介绍
直播带货是“内容+电商”这种新商业模式最火热的应用之一,传统互联网电商如PDD、JD等均已上线直播带货平台,众多内容赛道玩家如抖快也加大直播电商的投入。淘宝直播作为直播带货领域的先行者,近几年一直保持高速增长,据集团2021财报显示,淘宝直播年GMV已超过5000亿元,同比增长超90%,是集团营收的重要组成部分,同时打造出了薇娅、李佳琦等一众IP明星,形成了平台、商家、达人共赢的良好局面。
淘宝直播相比于其他内容形式,如短视频、图文等,最大的特点是实时互动,商家和达人在直播间实时进行商品展示、开展营销活动,与用户互动中完成宝贝种草、圈粉、收割变现。如何将这种实时的内容高效率地分发给相应的受众就是我们直播推荐算法团队要解决的问题,淘宝直播分发的主要场景有淘宝首页宫格的频道页、首页猜你喜欢直播feeds流等一跳场景,以及承接一跳点击进入直播间的二跳场景全屏页。全屏页提供了一个沉浸式的信息流展示形式,其承担着对用户一跳refer(引导用户进直播间的一跳点击主播)兴趣点的深度挖掘与扩展,以及对用户隐/显式正负反馈的实时感知和决策。针对前者,精排模型做了相当多的工作,保证了refer的相关性和推荐的准度,考虑到精排模型体量已经很重的情况下,如果对用户和主播实时行为建模再放到精排中就显得很臃肿,因此针对用户的正负行为反馈以及直播间实时状态的感知决策自然就落在重排阶段。
本文旨在分享正负反馈序列建模与多目标优化在淘宝直播排序上的实践经验,主要主要分为以下几个部分:第一部分描述了直播二跳场景重排序面临的一些问题以及期望达到的一些效果;第二部分基于实际的业务问题进行建模,核心优化点主要包括政府反馈序列建模和多目标优化;第三部分是模型在线上取得的真实实验效果;最后总结了算法要点,并指出下一步需要解决的重要问题。
问题描述
全屏页重排主要是解决用户和主播实时行为反馈建模的问题,在精排保证个性化和推荐准确度的基础上,能快速感知端上行为,解决用户下滑过程中对感兴趣主播和不感兴趣主播实时挖掘和决策的问题。目前全屏页推荐的请求特点是每次端上请求多个结果,正常情况下只会展示一个,每次滑动会重新发起请求,因此在这里我们使用point-wise而非List-wise的模型结构来优化效率,同时我们还期待重排模型能达到以下几点要求:
- 实时感知:模型能实时感知用户侧的实时观看互动行为和主播侧直播间实时粉丝互动成交状态;
- 正负反馈:根据用户实时的正负反馈信号决定推荐的结果,改善用户体验;
- 多目标:提升停留时长、点赞、关注、分享、评论等内容分发指标的同时,兼顾宝贝点击、购买等电商成交指标,突出“内容+电商”的场景特色。
根据上述几点要求,我们设计了一套基于实时正负反馈的多目标轻量级重排模型,接下来将详细阐述模型的设计思路和结构。
重排模型
整个模型的核心结构如图1所示,主要由embedding层、主播与用户兴趣表达层、多目标学习层组成。其中输入层所用到的用户和主播侧特征主要为实时特征,用户实时正负反馈的兴趣表达采用序列残差学习的方式,上层多目标学习层使用类MMOE的算法框架。下面将分别对各模块做进一步描述。
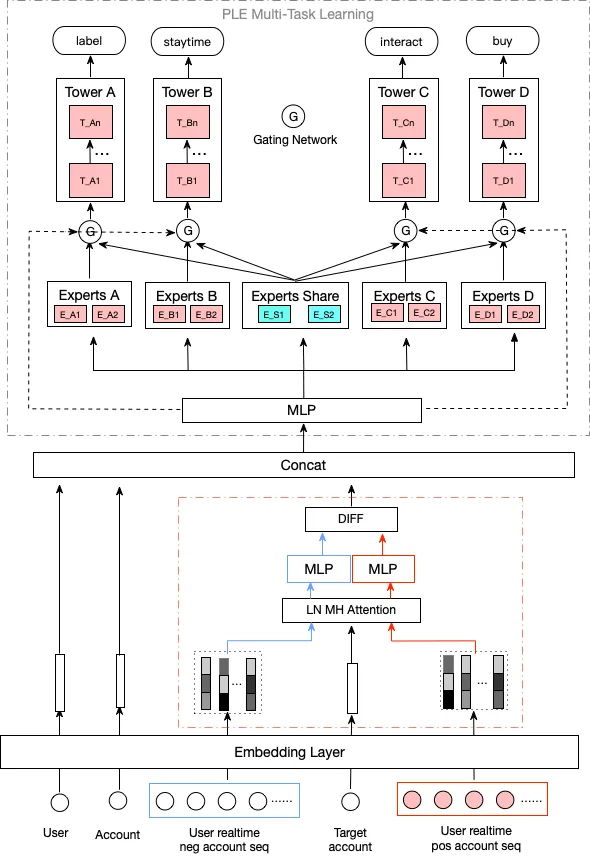
图1 多目标实时正负反馈模型
实时特征
用户侧
用户侧实时特征主要是两个实时正负反馈序列,如右侧图2所示,用户实时观看的直播流以实时消息的形式发送到Flink节点中进行预处理,然后实时转储到igraph表中,最后通过HPF(High Pass Filter)选取正反馈序列positive seq;通过LPF(Low Pass Filter)过滤出负反馈序列negtive seq。两个序列作为后续进行正负兴趣表达学习的输入信号。
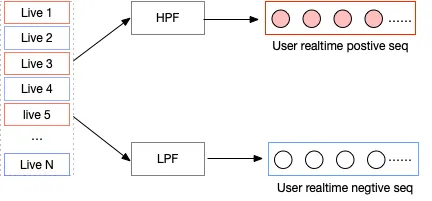
图2 实时正负反馈序列
主播侧
主播侧实时特征主要包含一系列直播间实时统计信息,从手淘客户端采集如观看uv、点赞、关注、评论、分享、宝贝袋点击等实时消息,然后flink节点中进行数据聚合形成直播间统计特征,另外主播正在展示和讲解的topN商品信息(宝贝类目、品牌等)也会引入到模型的特征层中丰富主播表达。
正负反馈
对比残差建模
目前针对用户兴趣建模的主流方式是对用户的正向行为序列进行信息的提取与匹配,如DIN, DSIN,DIEN等,在这里我们还引入了用户隐式负反馈的信号,目的是解决用户快速滑动且停留时间很短的情况下系统还是推类似主播的问题,通过正负反馈行为的建模,实时感知用户的喜恶,并及时干预接下来的推荐内容,有效提升用户体验。如图1中红色虚线框所示,正负反馈序列在与target主播进行attention提取出匹配信息后再做差,即: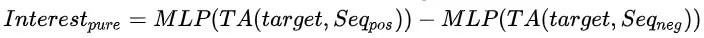 ,其中,MLP:多层感知机,即三层全连接层;TA:target attention[2],基于Transformer[1]改进而来的attention信息提取器,Transformer模型最早来源google的论文《Attention is all you need》,在NLP领域大放异彩,其self-attention机制不仅在语言建模上取得重大进步,在CV和搜推中的应用也逐渐扩大,其主要结构如图3所示,核心组件为multi-head self-attention,计算公式如下:
,其中,MLP:多层感知机,即三层全连接层;TA:target attention[2],基于Transformer[1]改进而来的attention信息提取器,Transformer模型最早来源google的论文《Attention is all you need》,在NLP领域大放异彩,其self-attention机制不仅在语言建模上取得重大进步,在CV和搜推中的应用也逐渐扩大,其主要结构如图3所示,核心组件为multi-head self-attention,计算公式如下: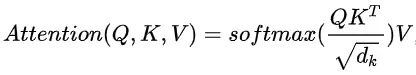 , 其中 Q是Query,K是Key,V是Value。
, 其中 Q是Query,K是Key,V是Value。
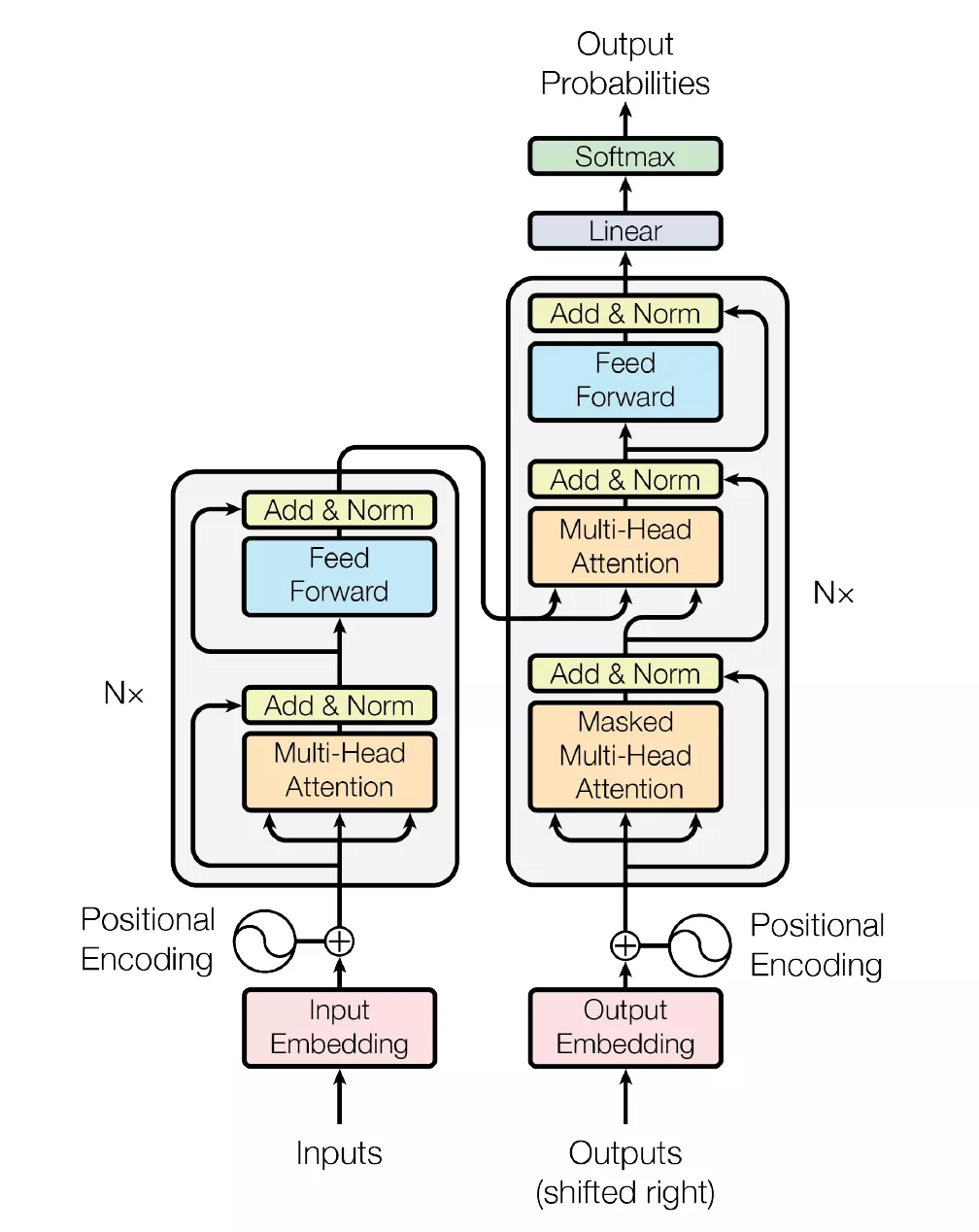
图3 Transformer主要结构
在Transformer的encoder部分的self-attention中Q、K、V均指输入序列本身,而target attention中query是指待打分的候选主播,key和value指用户的行为序列。
label-aware triplet loss
为了更好的学习正负序列之间的区分性,在这里引入metric learning的loss function来辅助优化序列学习。考虑到待打分的主播与正负序列表达构成一个triplet组,因此自然而然想到用triplet loss[3]的形式,triplet loss是度量学习中一种重要的loss function,如图4,其原理是通过anchor与postive尽可能靠近,anchor与negative尽可能远离的度量学习方式,使得object之间的embedding表达更具有区分性。
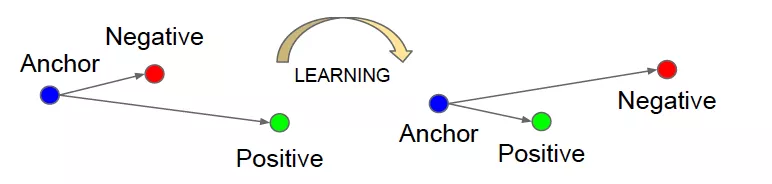
图4 标准triplet loss学习原理
标准的triplet loss公式为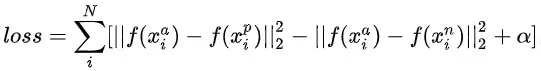 ,与标准triplet loss不同的是,我们的样本中正/负样本和每个样本对应的用户正负反馈序列已经确定,因此对于正样本我们可以采用标准triplet loss的形式,对于负样本则需要进行取反操作,因此在这里我们设计了一个label aware triplet loss来辅助优化序列学习(图5)。即
,与标准triplet loss不同的是,我们的样本中正/负样本和每个样本对应的用户正负反馈序列已经确定,因此对于正样本我们可以采用标准triplet loss的形式,对于负样本则需要进行取反操作,因此在这里我们设计了一个label aware triplet loss来辅助优化序列学习(图5)。即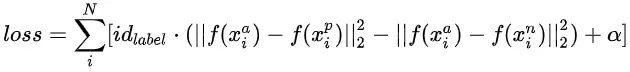 ,对于正样本
,对于正样本![]() 为1,对于负样本
为1,对于负样本![]() 为-1。
为-1。
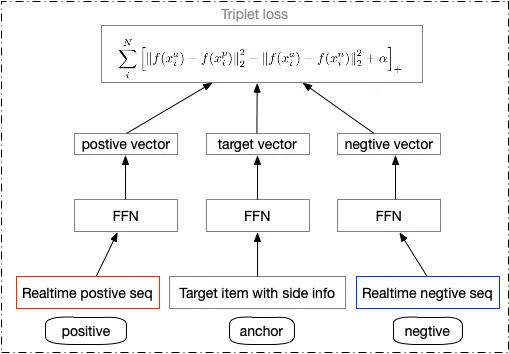
图5 label-aware triplet loss
多目标
为了满足推荐场景不同业务指标的要求,多目标学习基本是很多推荐场景的标配,其整体框架如图6所示。
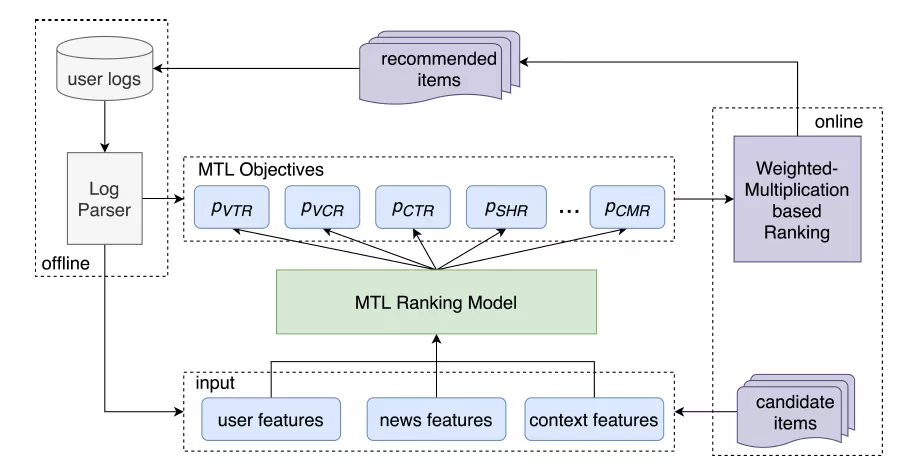
图6 多目标学习一般框架
直播场景中存在多个业务指标优化的诉求,内容指标主要有停留时长、点赞、评论、分享等互动指标,电商指标主要有宝贝的加购、购买、gmv等指标。如何平衡多个目标之间的相关和冲突是一个值得深入研究在课题,在这里我们采用了task-specific experts结合share experts的算法机制,有效缓解传统MMOE类算法框架的“跷跷板”问题,即图7中PLE多目标学习框架[4]。同时为了减少label的稀疏性,我们将点赞、分享、评论、关注等互动行为合并成一个label,即interact;把宝贝加购、购买、成交相关的行为合并成一个label,即buy,这样既较少了模型参数,也减少了稀疏目标优化的难度。
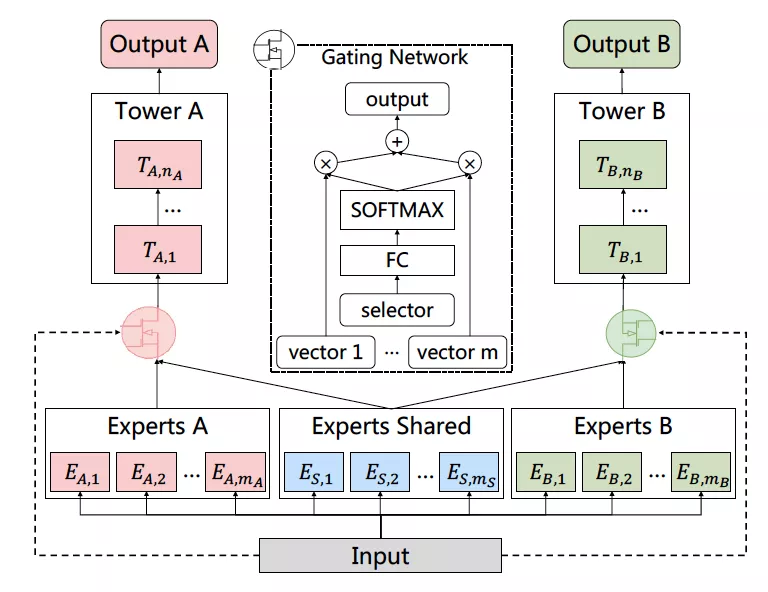
图7 PLE多目标学习框架
线上效果
在淘宝直播场景线上AB实验,整体收益如下:
- 核心指标:人均时长+4% ;
- 互动指标:人均点赞率+5.2%,人均评论率+4.0%,人均关注率+6%,人均分享率+5% ;
- 成交指标:人均成交提升20%+
目前模型已全量发布,模型在整体时长、互动指标和成交均取得正向收益。
总结&展望
以上是我们对淘宝直播全屏页重排的一个阶段性思考和总结,在淘宝直播这样一个实时互动的场景,实时行为的感知和决策是一个需要长期思考和优化的重点问题,目前随着我们对这个问题不断深入探索,不仅取得了线上效果的提升,也沉淀出了符合直播业务特点的技术思路。
在实时特征上,构建了用户正负反馈和直播间的实时感知链路;在行为序列建模上,正负反馈序列的对比残差学习实时感知用户喜恶,即时决策推荐结果,提升用户体验;在多目标学习上,引入PLE算法在互动指标上也取得效率的平衡。
未来在重排阶段将加强用户兴趣的探索与利用,在满足推荐准度的同时尝试探索用户新的兴趣点来破圈,目前随着RL在推荐领域的快速发展,基于RL的重排模型将在直播这种实时交互很强的场景具有不小的应用潜力,希望能同各位搜推广的同学一起交流反馈,在业界能有更多的技术落地点。
参考
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commerce recommendation in Alibaba[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[3] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, 2015. 2, 3, 7
[4] Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. In Fourteenth ACM Conference on Recommender Systems. 269–278.





