

淘宝视频是如何分类的?又是如何保持不同类别视频样本得到相对均衡?又是如何应用的?
前言介绍
背景
在推荐系统中,分类体系在内容圈选、招稿以及投放的过程中都发挥着重要的作用。产品运营可以借助分类体系来圈选内容,例如统计不同领域的视频的供给和用户行为等,对于内容供给不足但比较重要的类目,可以定向招稿。
在投放环节,分类体系可以帮助系统更好的聚焦于用户感兴趣的大行业方向。
例如某个用户比较感兴趣的是美食、3C数码、美妆这几个领域,如果我们的分类体系构建的足够细,那么我们可以进一步知道他在3C领域对手机、耳机更感兴趣,而对电脑、相机没有太多兴趣,从而召回用户感兴趣的内容。
淘宝视频分类的难度
内容分类与商品类目的区别
怎么挑西瓜是“美食_食材选择”,怎么吃西瓜是“美食_水果”,演示吃西瓜是“美食_吃播”,对比不同种类的西瓜是“美食测评”,拥有相同商品的视频有可能表示了不同的类型。
教如何做西瓜拼盘的视频是“美食_教程”,但挂的商品可能是西瓜刀,所以挂商品类目可能和视频类目差异较大。
所以商品类目是无法和视频分类词一一对应起来的,但是能作为一个辅助信息帮助我们进行判断。
例如“美食_烘焙”的视频,挂的可以是烘焙用具的商品,也有可能将视频类目归到“家居日用_厨具”,这就出现了视频类目与商品不一致的情况。
多模态分类VS文本分类
淘系视频很多title和summary是无意义的,例如很多title、summary是“xxx.mp4”、“北京时间xxx”,或者是比较抽象的描述,例如“很多女生都在用”。
单纯用这些文本很难进行视频分类。
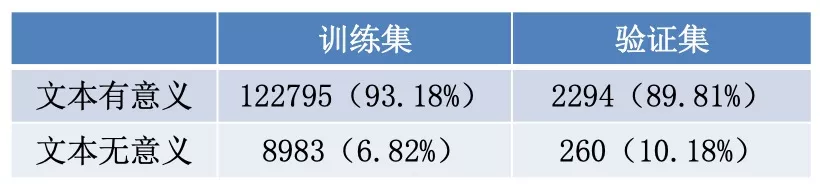
我们统计了训练集和验证集上有意义文本的占比,发现无意义的文本占到了7-10%的比例。
模型上的效果也验证了多模态分类的必要性。
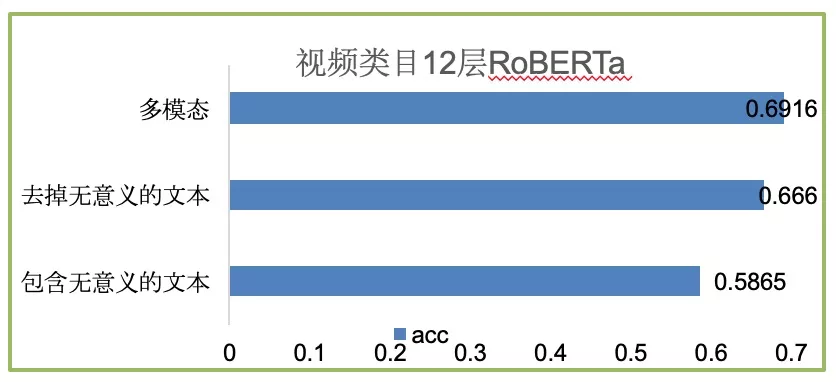
而且仅仅通过文本进行判断还可能出现较大的偏差,例如这样的视频:
title:小米手环四,开箱初体验。
summary:我们拿出手环来测试,功能多,有测心率测步数,滑动很流畅不卡顿。
从视频的title、summary来看这是一个“开箱测评”类型的视频,但其实这是一个“推荐”视频。
视频内容分类需要对视频内容有完整的理解。
很多细节都需要从视频画面中提取,而不仅仅是商品信息或者文本就能解决的。
短视频分类体系定义
构建规则
为了能够更好的对用户兴趣领域进行划分,我们希望能构建出粒度较细的分类体系,在新版分类中,我们最终构建出3000+个叶子类目。
分类体系的构建建立在以下几个原则的基础上:
- 分类间互斥:分类词之间没有重叠。但是在实际中,不可避免存在一些重叠,例如 美食里的 “烘焙”和“零食小吃”,用“烘焙”的方式做出来售卖的零食,放在两个类目中都有一定的道理。
- 从视觉上可分:从视频画面上可以进行划分。这是在视频内容理解技术和业务需求之间做的一个平衡。很多淘宝视频附带的title、summary有可能是无意义的文本(例如很多title是xxx.mp4)、或者是比较抽象的文本(例如“女神都在用的宝贝”),在缺乏足够的文本辅助信息的情况下,我们需要保证从视频画面上就能进行区分。
训练数据制备
视频分类的语义层次较高,部分类目的范围定义也比较复杂,我们选择用监督学习的方式构建模型。
由外包的同学按照视频内容分领域对淘宝PGC视频进行标注,25个领域总标注了28万的样本。
采样
空间密度采样可以用较少的样本覆盖尽可能多的空间范围,使用同样数量的训练样本和相同的模型,空间密度采样能比随机采样提供更好的泛化能力。
样本不均衡
从淘宝视频中随机/空间密度采样挑选样本作为训练集容易造成各个类目上分布很不均衡的情况。例如服饰、母婴、3C是大的领域,而旅游、美甲是小领域,小领域上的分类词很可能会有样本数量不足的情况。为了减少样本不均衡对分类结果的影响:
- 一方面我们利用商品类目和分类词之间的相关性,对少样本类目进行扩展;
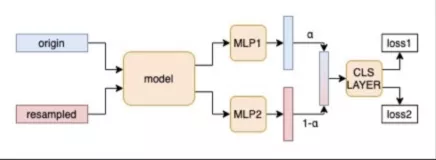
- 另一方面我们在训练的时候进行resample:
在训练时,模型会接收到两种分布的输入,分别是正常分布和重采样分布。通过同样的特征提取模型后,输出为两个向量。
随后模型会进行MIXED的做法,将两个向量融合,再计算loss来优化模型。随着训练的持续,模型的重心会逐渐从正常分支转移到重采样分支。
在5个领域的数据上进行实验,内容分类的准确率从64.2%提升到68.8%。
主动学习
淘宝视频分类本质上是一个open-set,不断会有新类型的视频产出,有新的类目需要加入到分类体系中,为了能处理新的视频类目,我们希望模型能持续的进行小的迭代更新。
为此我们构建了主动学习链路,通过密度采样,尽可能减少人工标注的样本量,并使模型能适应淘宝视频整体样本分布的变化。

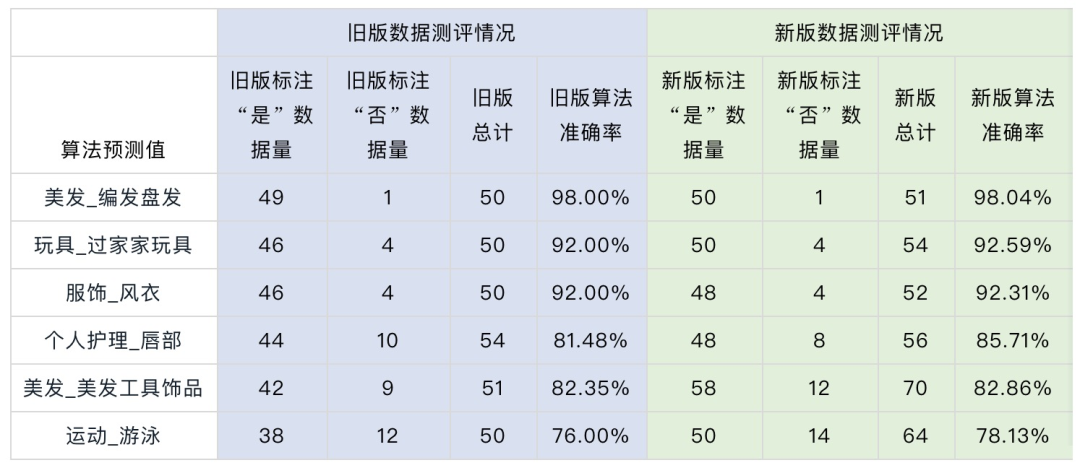
密度采样:用旧版本模型在所有低置信度视频上的embedding向量,进行聚类,按照各个聚类上的样本分布采样得到新训练集。

单轮主动学习部分类目效果:
多模态融合识别算法
整体架构
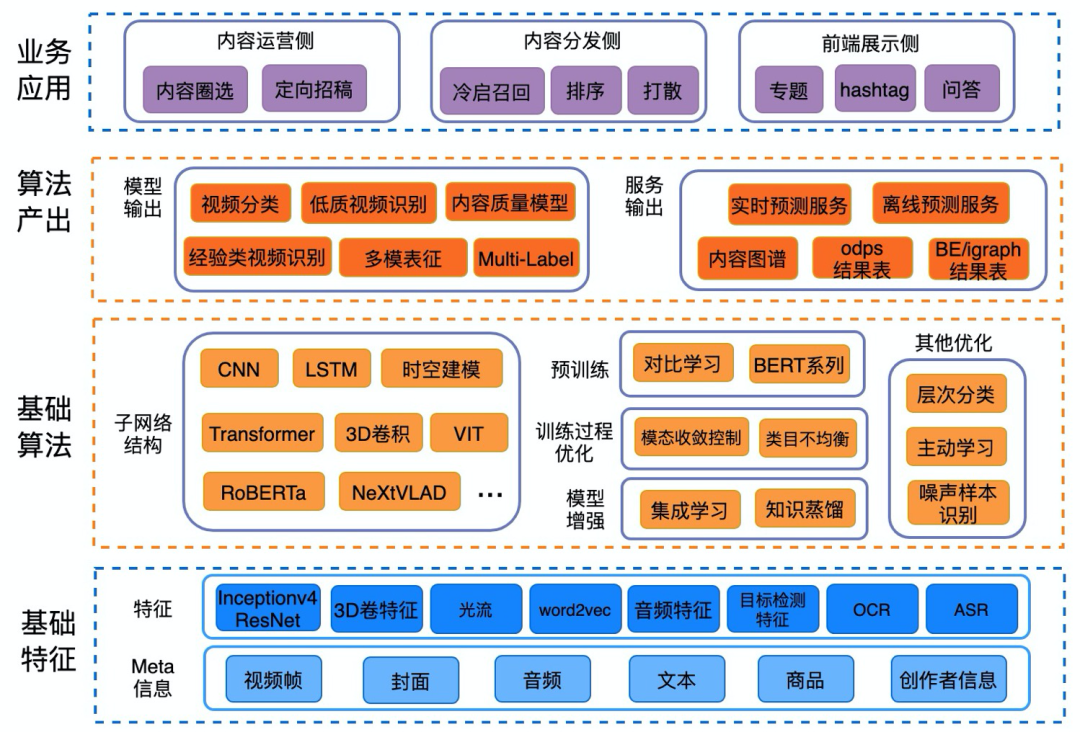
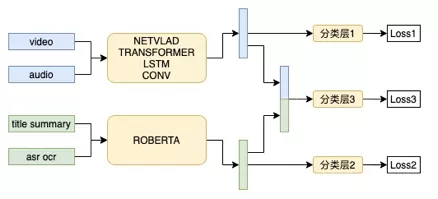
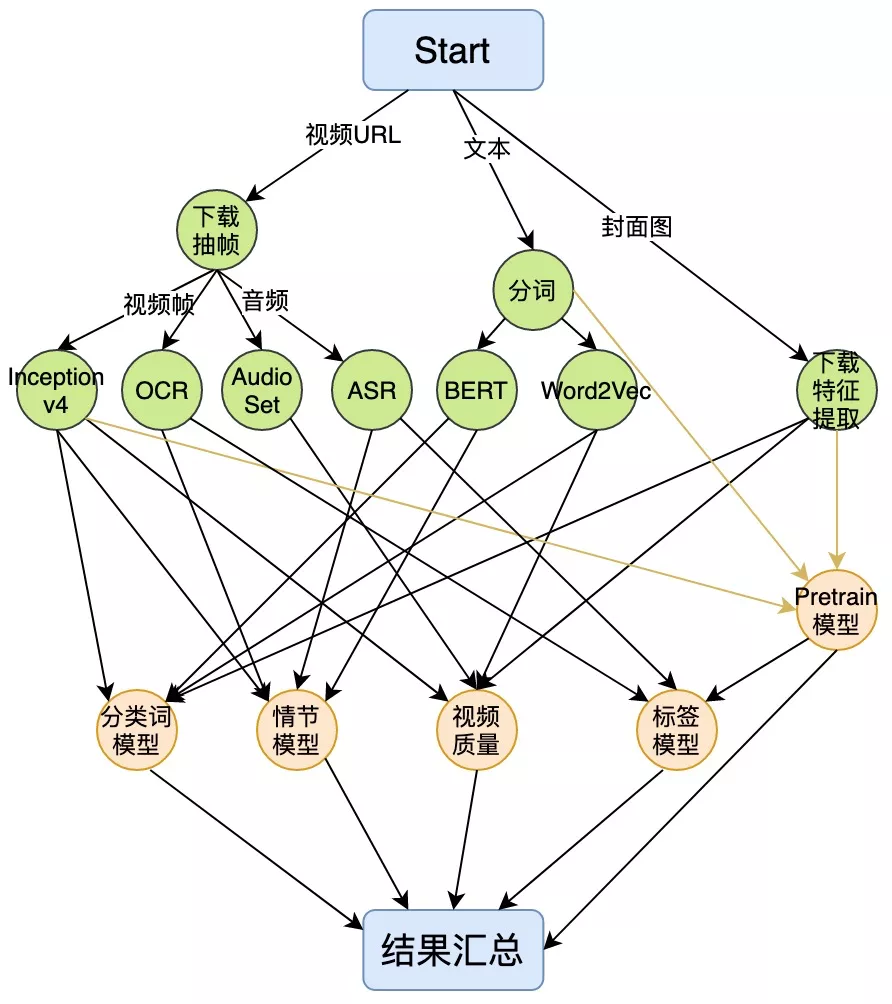
上图是我们视频分类的整体架构,我们对视频相关的信息(视频帧、文本、商品等)提取特征,并构建各个模块的子网络,融合后进行类目的预测。
除了视频分类,我们的模型还应用于低质识别、内容择优、经验类视频识别、多模表征、多标签预测等多种任务,并取得了较好的效果。
视频多模态融合分类模型结构
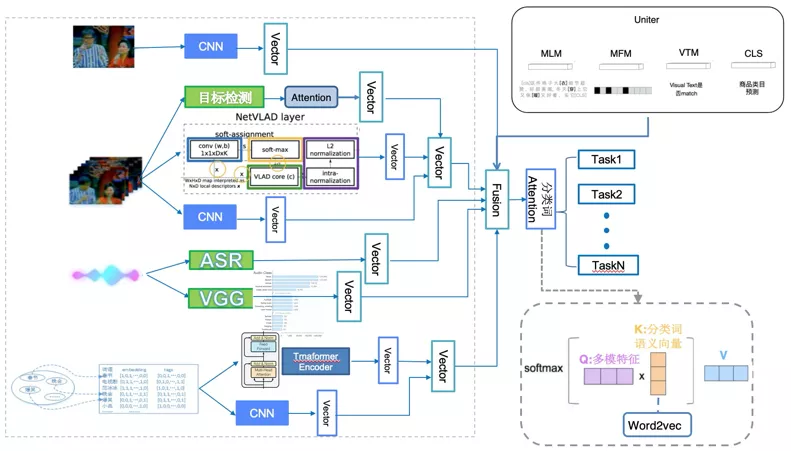
视频帧模块优化
全局特征优化
视频内容分析的其中一个难点是从视频帧大量的无语义像素中抽取出高层语义信息。
其中一种做法是先把视频帧转化成向量,例如在imagenet上训练的Resnet、inception网络,把视频帧输入到模型中,提取embedding向量。
在把视频帧转化成向量后,我们可以用CNN、LSTM、NetVLAD等对视频帧序列进行建模。
Nestvlad:在NetVLAD的基础上,我们做了改进,得到NestVLAD
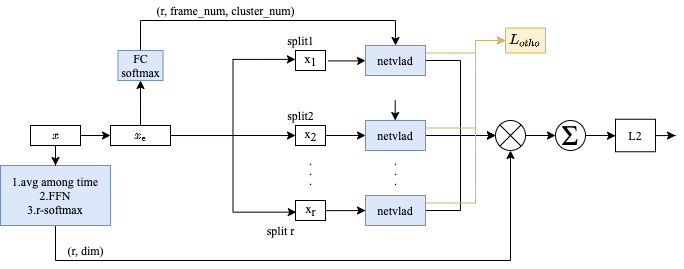
Netvlad是聚合数据的描述子的算法,通过计算各个描述子到聚类中心的残差的加权和来得到数据的表征。
Nextvlad将视频的描述子映射到不同的子空间,然后计算每个子空间的描述子到聚类中心的残差加权和,最后通过一个gate相加来得到数据表征。映射到子空间能大大减少模型参数。
Nestvlad将视频描述子映射到不同子空间,然后计算每个子空间的描述子到聚类中心的残差加权和,最后在通过一个r-softmax聚合。
此外我们还加入了聚类中心之间的一个正交loss,尝试拉远聚类中心的距离,从而得到更泛化的表达。
NeXtVLAD把视频帧向量划分成多个子向量,然后这些子向量在同一组聚类中心上求残差,NestVLAD为每个子向量分配了不同的聚类中心组,并且用原始的特征计算softmax,可以兼顾全局信息。
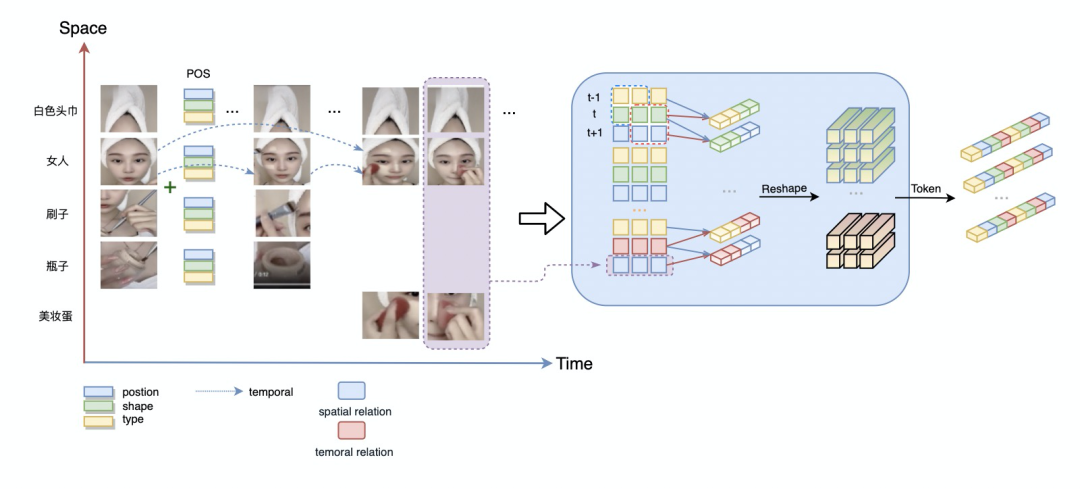
时空特征优化
把视频帧转成一维向量所保留的信息量取决于特征提取模型的任务,通常会损失比较多的信息,例如空间关系,物体状态等,其中有些信息是视频分类词任务所需要的。
patch上的时空建模可以更好的捕捉各个细节在时间上的变化,以及各个patch之间的relation,保留所有的原始信息。
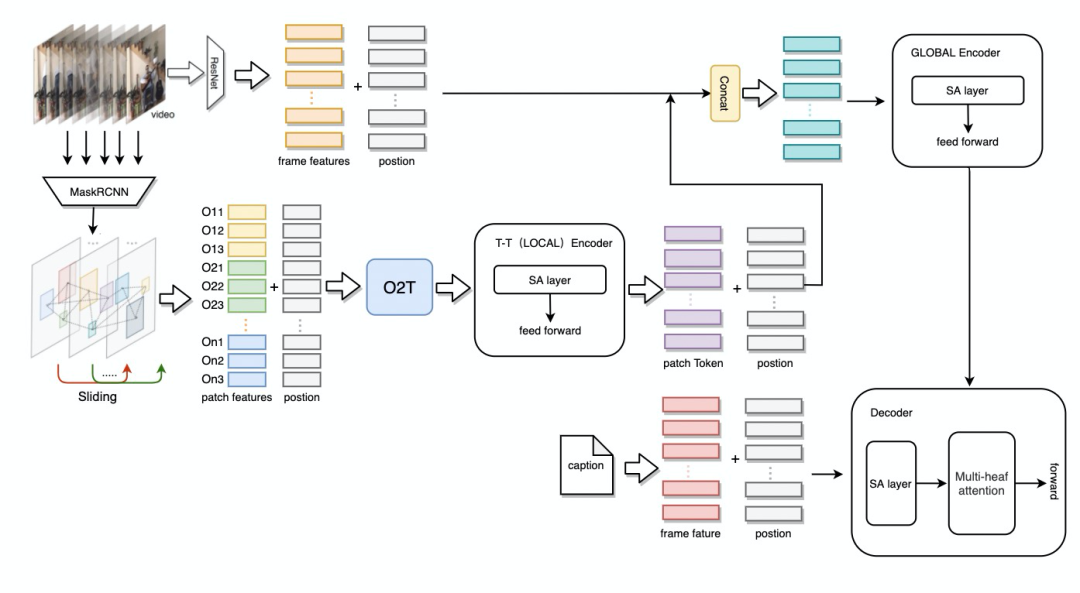
例如下图中可以通过时空建模获取手的动作变化和物体的变化。



Video Caption
在时空建模思路的基础上,我们考虑在Video Caption中对视频中的objects构建时空关系,从而获取较好的objects关系和变化信息。
O2T(objects-to-token)模块中首先附加patch的位置,长宽,类型,再从Tokens-to-Token的思想出发,递归的把近邻d的Tokens集成为Token来建模同一帧内object之间的相对位置关系以及同一object的时序关系,以提取object的运动轨迹,几何变化等信息。
对比学习
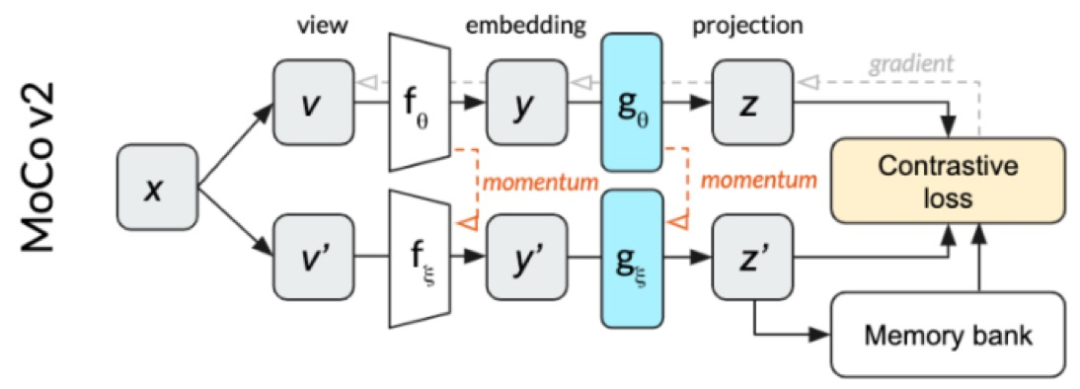
另一种特征优化方法是对比学习。
淘宝场景下我们有大量的无标注视频,通过对比学习,我们可以学到不同图像之间的差异点,从而也保留了淘宝场景下足够多的信息。
目前主流的对比学习有SimCLR、MoCo等,他们都是通过“让数据增强前后的图像embedding向量尽可能接近,不同图像embedding向量尽可能远离”来学习图像的表征。

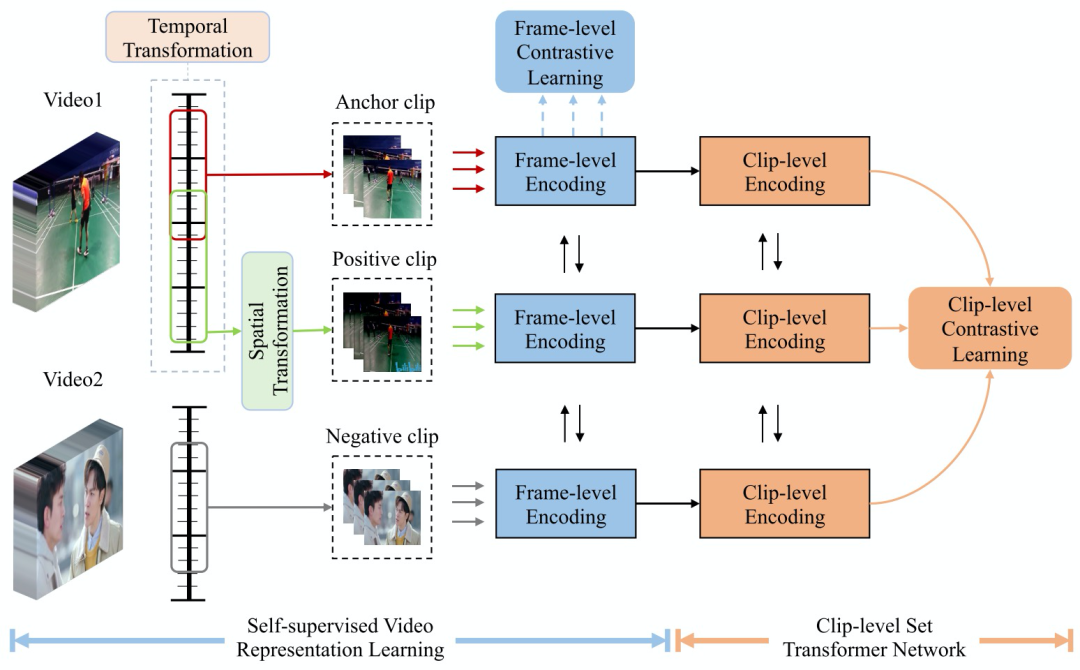
 我们也希望能用类似的方法在视频上得到类似的效果:同一个视频的帧/片段尽肯能接近,不同视频的帧/片段尽可能远离,从而学到较好的视频帧/视频片段的表征。
我们也希望能用类似的方法在视频上得到类似的效果:同一个视频的帧/片段尽肯能接近,不同视频的帧/片段尽可能远离,从而学到较好的视频帧/视频片段的表征。
文本模块优化
BERT类预训练模型在文本分类上取得了很好的效果,我们也考虑把预训练的优点结合到我们的模型中。
我们去掉了淘宝视频title、summary中无意义的文本。
并把较短的文本concat,得到共计500w段文本,用于RoBERTa的预训练。
CNN卷积网络捕获远距离依赖的能力较弱,而RoBERTa多层attention可以很好的建模长依赖。
最终单文本情况下比CNN和Transformer有显著的提升。
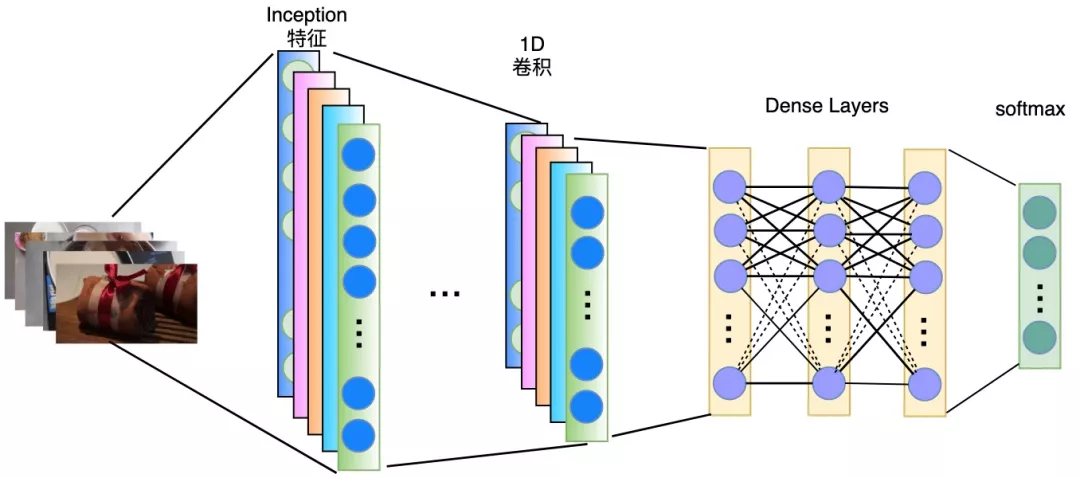
1D CNN卷积模型,捕获远距离依赖较弱
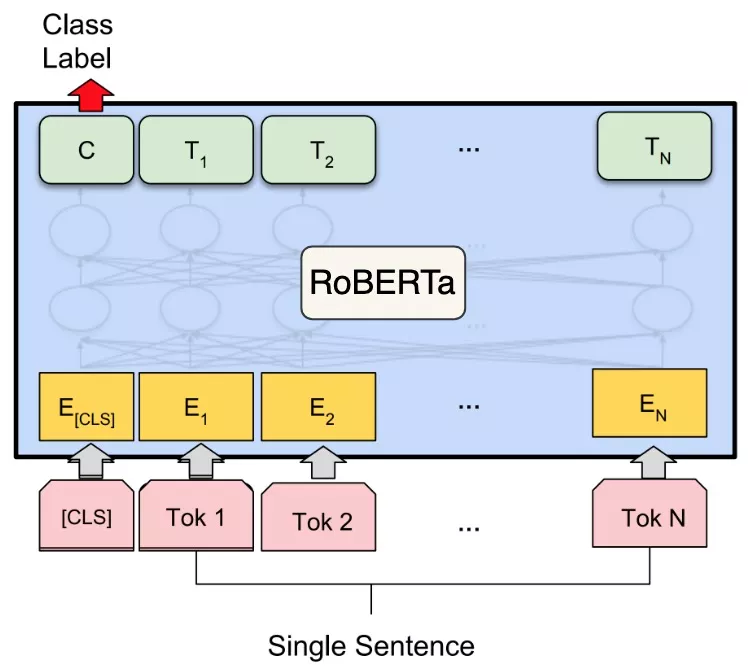
RoBERTa
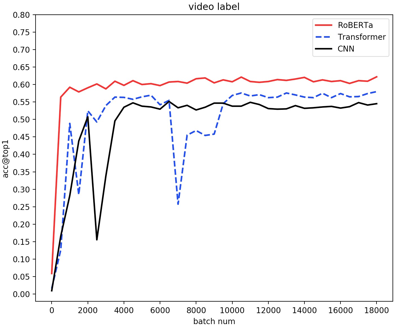
由于视频分类词模型是一个多模态,多模块,较为复杂的网络,为了得到较高效率的文本模块,我们对RoBERTa的深度和宽度做了实验对比,发现在分类词任务上深度相比宽度更重要。

同时我们使用知识蒸馏的方法来确保小的网络也能得到比较好的效果,用网络较大的teacher给网络较小的student提供额外的训练信息。


Teacher网络对比
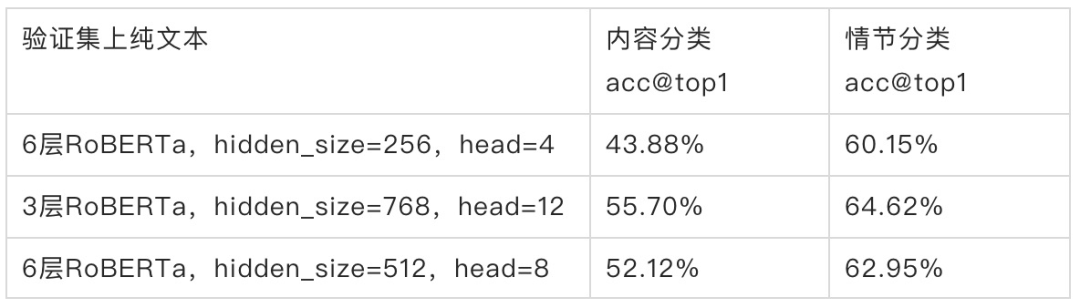 Student网络对比
Student网络对比
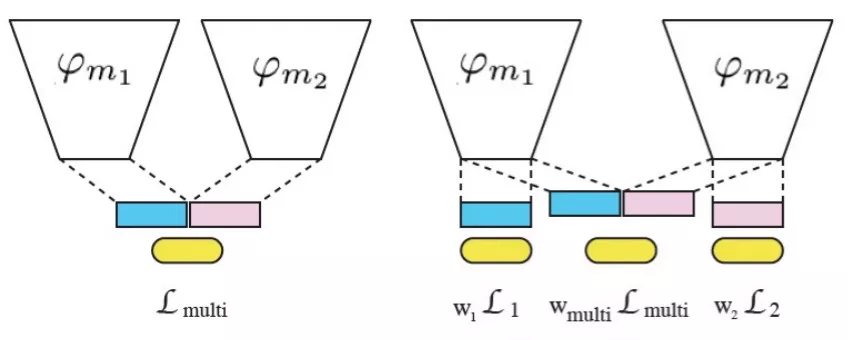
把RoBERTa作为文本子模块加入到大模型中进行finetune时,我们考虑到不同模态在训练的时候需要的learning rate可能不同。我们尝试了以下几种策略:
- 各个模态使用相同的learning rate;
- RoBERTa模块freeze,finetune过程中参数不更新;
- RoBERTa模块使用较小的learning rate,效果优于上面两种;
- 根据各个模态上的loss变化来设定learning rate,在这些方法中效果最优
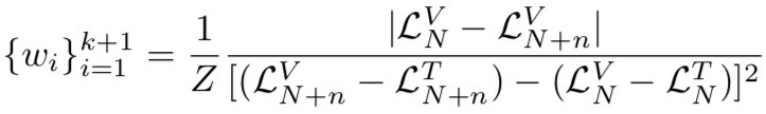
![]() 是第N步在valid集合上的Loss ;
是第N步在valid集合上的Loss ;
![]() 是第N步在train集合上的Loss。
是第N步在train集合上的Loss。
视频帧-文本联合模型
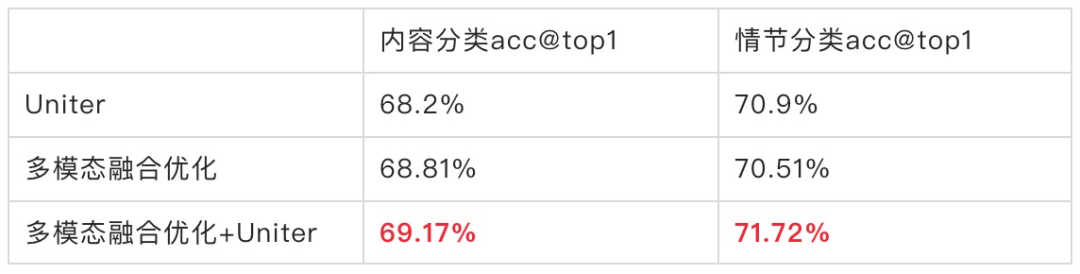
在VideoBERT,越来越多的视频多模态预训练模型被提出,Uniter就是其中一种多模预训练模型,通过MLM、MFM、VTM、CLS等Loss,构建文本内部、视觉内部、文本与视觉对齐等任务,从而让文本和视觉除了学好自己本身的特征外,互相直接也做了对齐。
相比于多个子模块搭建的分类网络,Uniter的文本与视觉之间的相互作用更强,并且利用了大数据预训练,可以更好的学到视频的表征。
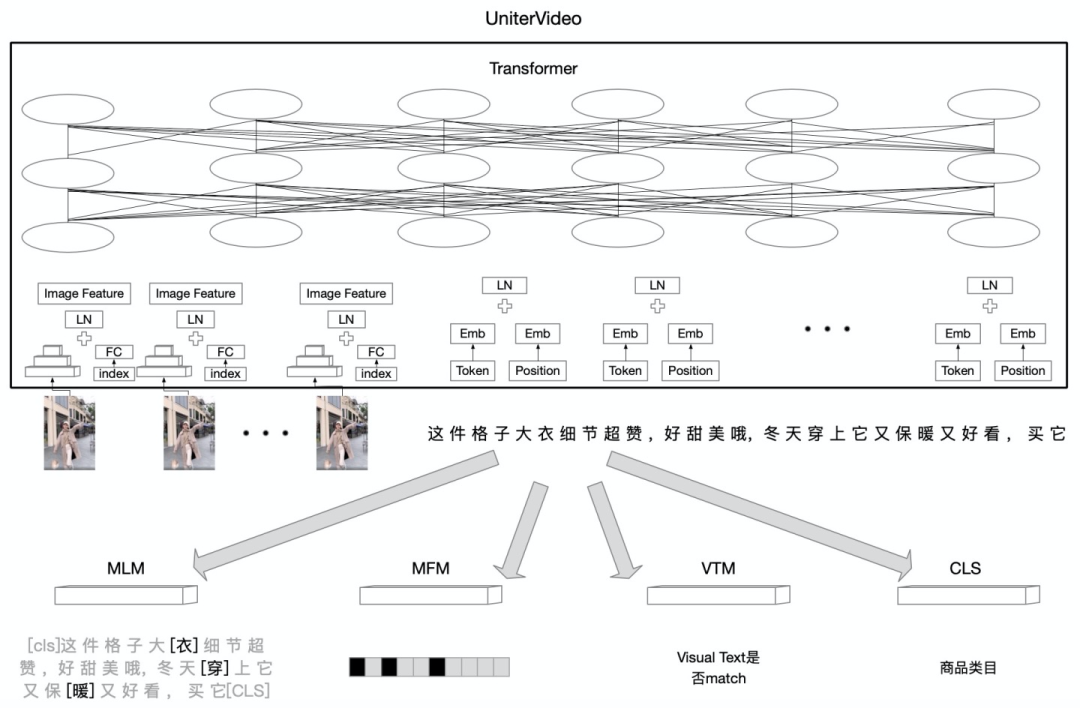
由于Uniter网络结构较大,很难把Uniter和其他子网络放一起端到端训练,所以我们提取出Uniter的embedding向量加入到模型中去,作为一种特征的补充。
预测模块优化
特征选择
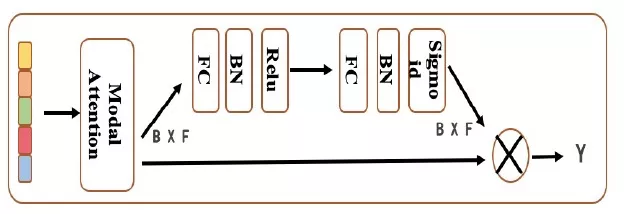
我们尝试了MOE和SE-context gate来对多模态特征进行筛选,选择对下一步分类最有用的特征。
MOE:不同模态对各个类目的作用不同,通过多专家决策模块对不同模态的特征进行选择,对相关特征进行增强

SE-context gate:不同于MOE,SE-context gate通过特征之间的依赖关系,抑制不相关的特征,在视频分类词中的到了比MOE更好的效果。
引入分类词语义信息
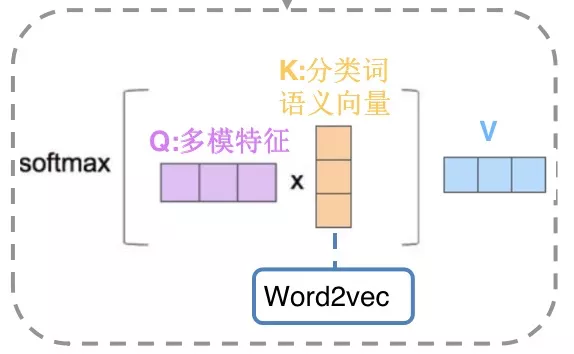
Attention:我们把分类名转化成word2vec向量,与多模态网络融合后的特征向量做attention,得到最终的特征向量。word2vec具有在全局文本中的side infomation,有助于多模态特征向量更好的了解整体的类目划分空间。
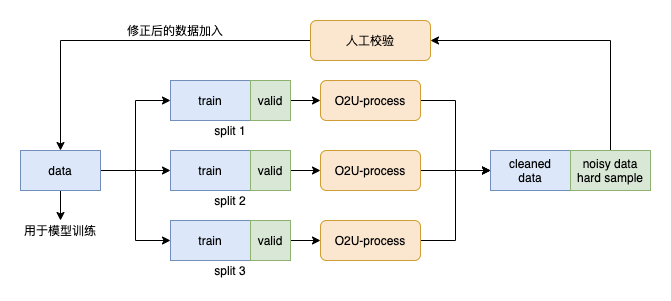
噪声样本识别
由于视频内容理解是一个语义层级比较高的分类任务。
因此在数据标注的时候,难免会遇到标注错误的情况。这会影响到模型的训练。
因此进行噪声样本识别是一个关键的步骤。
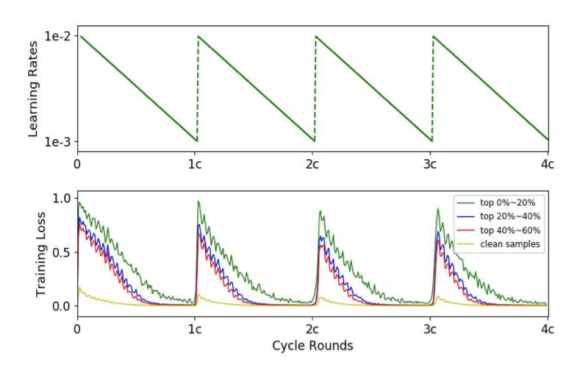
这里我们主要参考了集团内其他团队对噪声的处理《(2019 ICCV) O2U-Net- A Simple Noisy Label Detection Approach for Deep Neural Networks》。
对模型学习不好的领域,挑选出loss震荡幅度较大的样本。这些样本可能是噪声,也可能是难样本。
通过进一步地清洗数据,能得到更纯净的数据,从而让模型更好地理解数据。
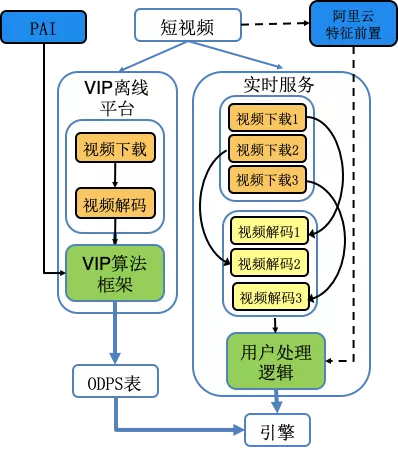
实时链路
为了更好的为业务提供服务,我们构建了离线链路和实时链路,离线链路是在PAI平台上搭建的daily任务链路,实时链路是在VIP平台MediaFlow上构建原子op和graph。
我们和计算平台的同学对视频分解、抽帧做了深度优化,一个淘宝视频的平均处理时长从最初的20多秒减少到4s左右,大部分视频都能在10s以内完成 下载、抽帧、提取特征(帧特征、文本特征、音频特征、OCR、ASR等)、模型预测整个流程。
目前实时链路已经在为首猜曼哈顿3分钟链路、内容中台视频审核提供服务。
下面上图是离线链路和实时链路整体框架,下图是分类词大graph的原子op和边的示意图。
业务应用
首猜打散
为了提高用户的浏览体验,希望在用户的一个session交互内,给他们推尽可能多不同类目的视频。
在同一个session内如果两个推荐的视频是在同一个叶子类目中,则认为这是一个bad session。
通过视频分类进行打散是在体感和效率上进行平衡。
视频分类从v1.0升级到v2.0版本,在效率持平的情况下,badcase减少了约7%,推荐多样性指标有大幅度提升。
首猜冷启动链路
模型的embedding向量用于冷启动召回作为一路召回,CRT(4.5895%)指标仅次于fans2c(粉丝召回)。
首猜全屏页主链路
加入到相关性模型中后,与基准桶相比,实验桶二跳视频相关性问题略有下降,多个视频推荐相同商品问题减少4.12%,有明显的好转。
分类模型embedding向量加入到首猜召回模型中作为一路召回,这路召回的CTR(10.53%)相比于其他路有很大的提升。
云主题挂载视频
为19362个云主题挂载一个相关的 知识教程/好物评测 视频。
淘宝短视频和逛逛
v2.0分类体系同时迁移到了淘宝内容中台和逛逛等业务场景,叶子类目数量从200左右增加到400+,且算法模型、标注额外增加的工作量很小。
v2.0版本叶子类目共计3000+,适用于搜索推荐等算法场景,对于创作者、运营的则可以在v2.0分类词树结构的基础上进行剪裁。
我们多模态分类模型在逛逛上也得到了比较好的效果:

淘宝经验导航
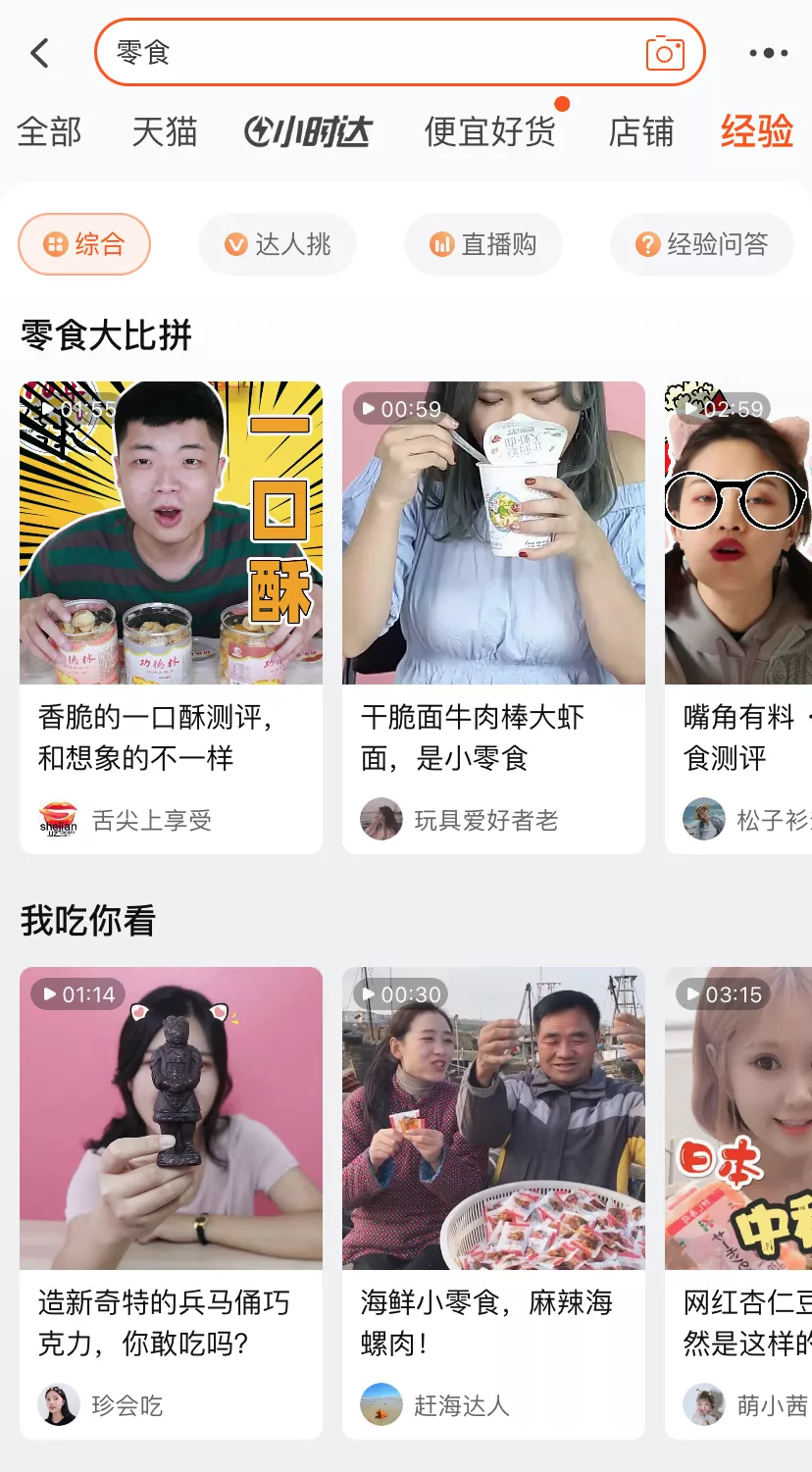
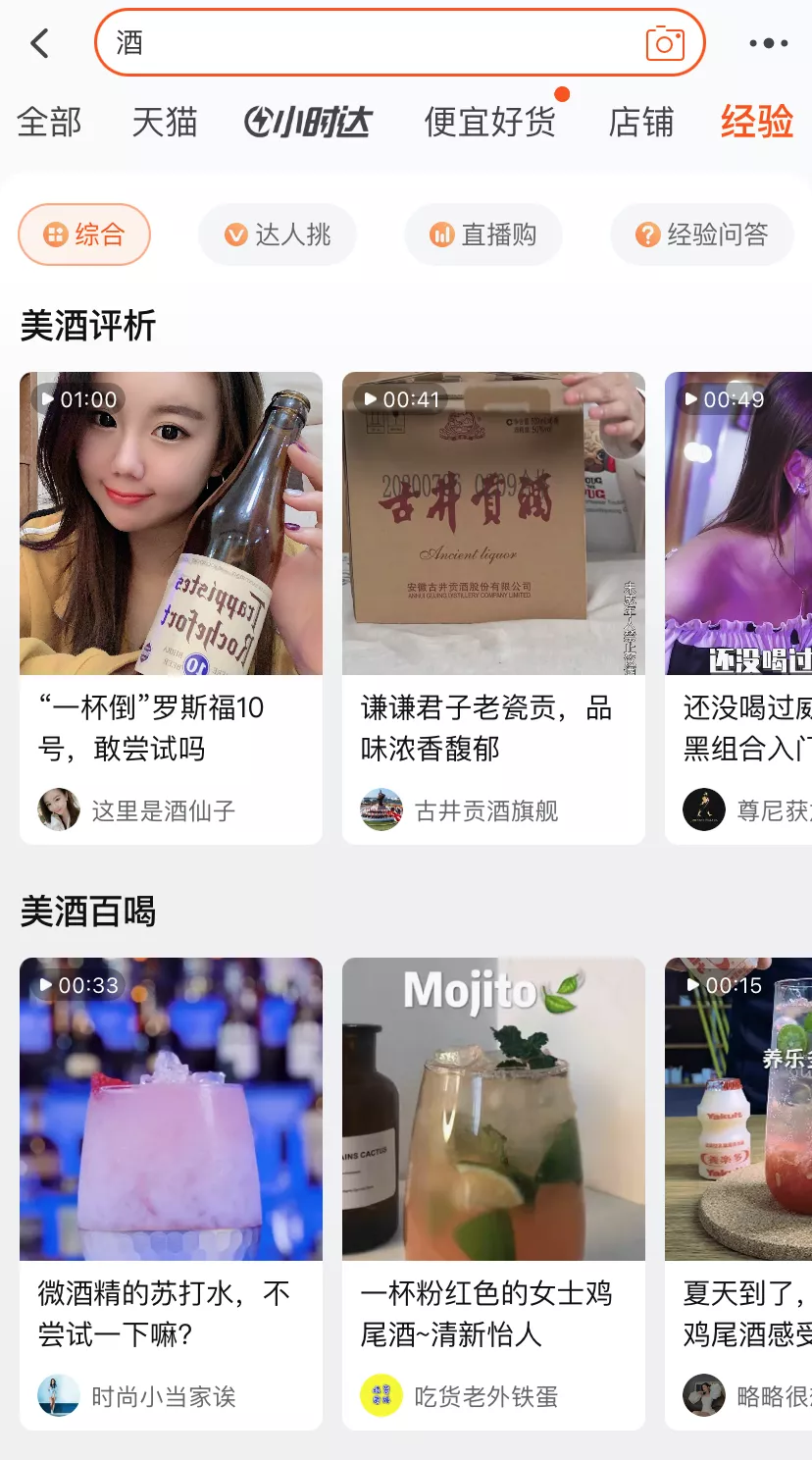
我们使用短视频分类的结果进行视频专题构建,物品+描述角度分类 可以构建一个栏目,通过组织相同物品的不同栏目,构建出一个专题。
例如下面两个case,在搜索零食、酒的时候会透出两个专题,两个专题分别包含了多个栏目,例如图中的“零食大比拼”“我吃你看”等。
分领域赛马
不同领域的视频用户行为存在较大的差异,例如很多用户喜欢看 萌宠_猫狗 的搞笑、软萌视频,但对 萌宠_宠物用品,更多是抱着购买需求浏览视频。
点击率、观看时长、成交量等天然存在差异。
对不同领域的视频在同一个赛道进行赛马,选择用户行为较好的视频分配更多的流量,对于那些平均用户行为较差的领域的视频很不公平。
所以需要分领域赛马选择优质的视频扩量投放。
视频分类模型根据视频的内容判断视频的类型,从而可以把视频分到相应的赛道进行公平竞争。
多模态分类模的沉淀和推广
我们的多模态短视频分类模型可以广泛应用于多种短视频分类任务。例如在淘系场景内,我们使用这个多模态分类模型来解决其他一些task,并取得了较好的结果:
- Howto视频识别:理解视频帧时间上的变化,判断视频是否是在讲述某些使用经验或者生活经验;
- 精品池视频择优:对文本、视频帧、语音等信息进行分析,判断视频是否是优质视频;
- PPT视频识别:根据视频画面判断视频是否是PPT类型的视频;
总结
我们的多模态视频分类模型在多个任务和场景得到了应用,特别在产品运营的招稿、内容圈选、统计分析和搜索推荐的分发效率和用户体验提升上起着重要的作用。
在多模态视频分类的优化上,我们分析了模型在任务上的缺陷,从训练样本处理、模态特征优化、特征融合等入手,针对性的做了大量的优化,在各个任务上都取得了不错的效果。
后续我们将继续在视频内容理解领域探索,除了多模态视频分类,也会在Vdeo Caption、Video Question Answer、Video Grounding等方向结合业务做深入的研究。
Reference
- 视频智能分析平台VIP及其在集团业务的应用 https://topic.atatech.org/articles/154983
- O2U-Net- A Simple Noisy Label Detection Approach for Deep Neural Networks 2019 ICCV
- NetVLAD: CNN archi- tecture for weakly supervised place recognition 2016 CVPR
- ActionVLAD: Learning spatio-temporal aggregation for action classification 2017 CVPR
- GhostVLAD for Set-Based Face Recognition 2019
- NeXtVLAD: An efficient neural network to aggregate frame-level features for large-scale video classification
- BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition 2020 CVPR
- UNITER: UNiversal Image-TExt Representation Learning 2020 ECCV
- FASTER Recurrent Networks for Efficient Video Classification 2020 AAAI
- Is Space-Time Attention All You Need for Video Understanding? 2021 Arxiv
- Self-supervised Video Retrieval Transformer Network 2021 Arxiv
- A Simple Framework for Contrastive Learning of Visual RepresentationsTing 2020 ICML
- Momentum Contrast for Unsupervised Visual Representation Learning 2020 CVPR
- An Empirical Study of Training Self-Supervised Visual Transformers 2021 Arxiv





