

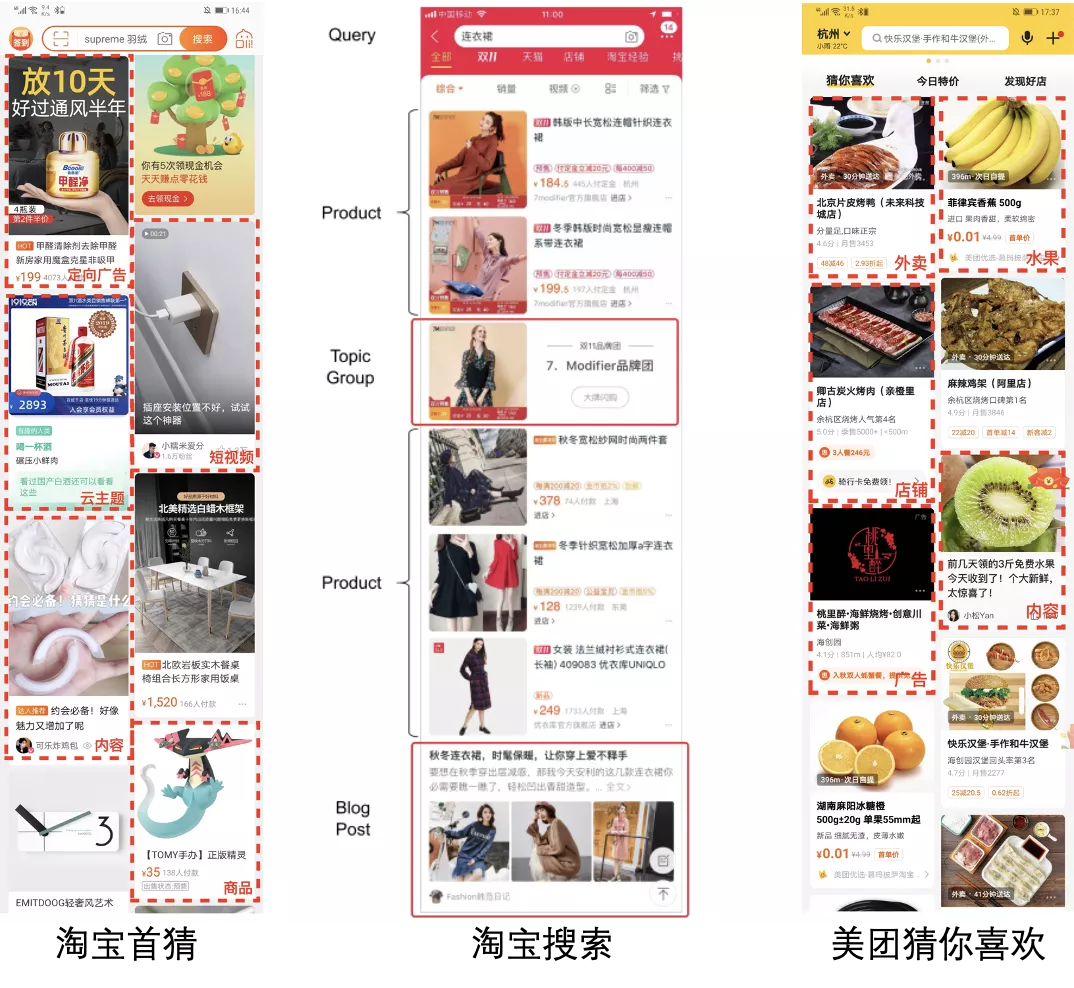
本文将介绍在我们电商首页部署的端上推荐系统EdgeRec,以及在端上推荐系统中的算法实践。
前言
双十一期间,我们业务完成了全面上云,云计算的发展保障了大促期间业务的稳定运行,承接了巨量的流量。在过去的这十年里,依托于大数据,云计算取得了非常耀眼的发展。随着云计算的发展,也面临着一些问题:互联网应用每天面临的大量请求,以及日益普遍的大规模神经网络在线部署,对云端计算产生巨大压力;随着5G的普及和带宽的增加,云端同时面临着巨大的存储压力;对一些实时性要求比较高的应用来说,与云端巨大的通信开销也是交互和体验瓶颈;同时云端“中心化”的计算模式也会带来运维成本和故障风险。
近几年,终端设备的计算与存储能力的快速发展,智能手机的性能成为主要卖点,各种CPU、GPU的快速迭代,内存越来越大,为计算带来了新的空间,端侧的工作不再只是。相对于云计算,端计算的优势在于下面四点:
- 数据本地化,解决云端存储及隐私问题;
- 计算本地化,解决云端计算过载问题;
- 低通信成本,解决交互和体验问题;
- 去中心化计算,故障规避与极致个性化。
实际上,端计算与云计算不是割裂的。在云计算时代,端侧主要负责信息的收集与展现,云侧负责大规模的计算与存储;在端计算能力逐渐丰富的今天,端侧的计算和存储能力也被利用起来,更多的端云联动能力被挖掘出来。比如,拍立淘将类目检测和物品检测能力放到端上,而将图片-商品召回、排序能力则放到云上;在谷歌输入法Gboard上,智能手机会根据用户的实时反馈首先更新用户个性化模型,并将更新信息回传云侧,云侧则会根据所有用户的反馈,聚合成新的统一输入法排序模型下发给每个用户,完成模型的迭代。结合端侧能力,提升互联网服务的质量与消耗,端云联动的能力越来越多的体现出来。
本文将介绍在我们电商首页部署的端上推荐系统EdgeRec,以及我们在端上推荐系统中的算法实践(部分已发表CIKM2020论文[1])。第2部分将介绍我们搭建的端上推荐系统EdgeRec整体架构,第3部分将介绍端上重排的问题与端上行为序列建模的算法方案,第4部分将介绍端上智能请求的背景问题与算法实践,第5部分将介绍我们在千人千模算法问题上的探索与算法实践。目前,EdgeRec日常为淘宝首页信息流带来13%的GMV提升。
端上推荐系统EdgeRec
信息流推荐系统的瓶颈
目前,信息流是业界搜索推荐产品的主流形式,其展现信息丰富、可持续交互的特性,使得包括我们电商首页瀑布流、我们电商搜索瀑布流、美团瀑布流、抖音全屏页等,都使用信息流作为主要推荐方式。当然,信息流推荐系统也面临着一些痛点,阻碍信息流的进一步优化。
痛点1:用户实时感知弱 / 决策慢
信息流推荐基于“分页请求”机制,仅在分页附近有调整机会。受限于资源消耗和用户体验,一般分页不会特别小。带来问题有:1. 分页过程中无法实时调整策略;2. 实时的意图获取和策略的调整次数太少。
用户的实时行为感知弱:上行数据延迟高:依靠端上实时上报日志->服务端实时解析->推荐系统实时查询的链路,回传延迟一般在10s-1min。
痛点2:云端存储和计算瓶颈
以我们电商平台首页信息流场景为例,日常2w+ QPS,大促峰值10w+ QPS,巨大的在线infer压力导致日常超时的情况时有发生,而大促期间也会面临降级;另外,一般需要存储60天的样本,云端面临巨大存储和训练资源消耗。
痛点3:“千人一模”的局限性
目前的推荐模型使用统一的模型,而“千人千面”源自于特征的个性化;高活用户主导全局推荐结果,20%的用户贡献了80%的训练数据;而每个用户数据分布并非IID,使用同一模型拟合并非最优。(图片引用自[2])。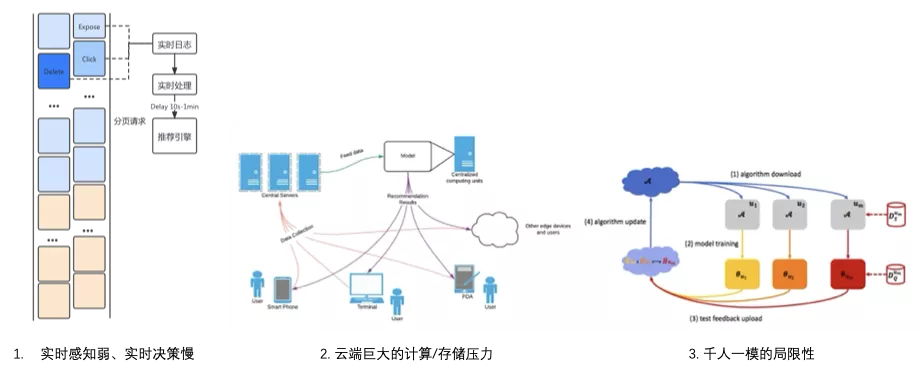
将以上三个问题进行细节分析。导致第1、2个问题出现的原因有两个,一是分页请求固定的分页时机,二是分页后固定的展现顺序。
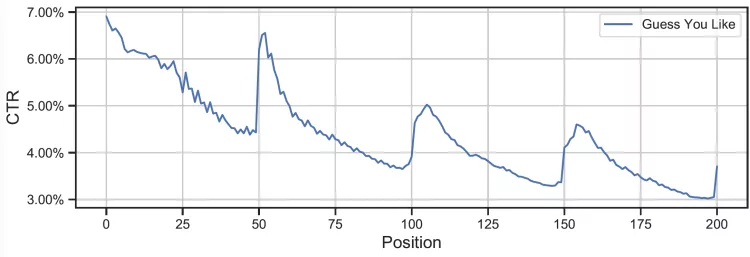
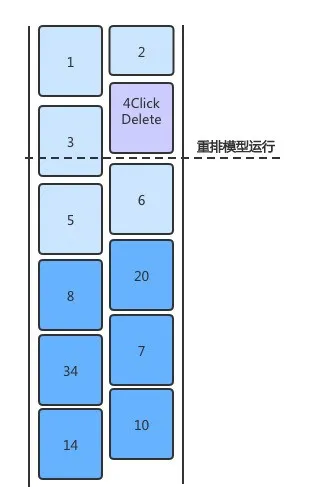
分页时机在分页推荐系统中是由规则决定的,一般是固定的分页大小。每次分页请求后,服务端可以拿到用户实时的意图,并基于用户意图进行召回排序。如下图,每次分页后用户点击率会增高很多,则是分页时机固定带来的。因此,分页大小固定带来的弊端是,分页时机与用户意图变更时机不匹配,同时资源消耗在不同用户中消耗是一致的。
展现顺序的固定,则导致了在分页内部卡片的顺序是无法调整的,无论用户进行了何种交互,推荐系统都要等到分页时才能重新调整排序顺序。如下图,每个分页过程中,用户的点击率是持续下跌的。
总结下来,分页推荐系统感知/决策慢、资源消耗固定的问题,根本原因是用户意图的变化与推荐系统的请求时机和商品展现时机不匹配。端上是请求的发起者和商品展现的终端,对用户行为有最实时的感知能力,因此,我们希望将请求决策和展现决策这两项最接近用户的任务放到端上,利用端智能的能力,进行进一步的优化。基于这个思想,在我们电商首页信息流推荐里建设了端上推荐系统EdgeRec,通过端上重排能力做展现决策,通过端上动态请求能力做请求决策,整体提升推荐系统的实时感知和实时反馈的能力。
端上推荐系统介绍
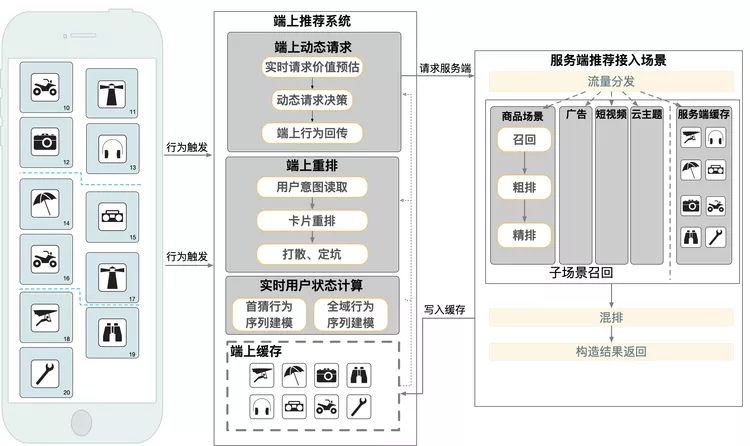
在展现决策方面,我们研发了端上重排能力,能够实时的对信息流中未曝光的卡片进行重新排序,实现用户意图的实时反馈,具体算法方案将在后续部分单独介绍。在请求决策方面,我们增加了端上智能请求部分,根据用户近期的行为,以及端上缓存中的卡片,实时的增加端上智能请求,将用户意图实时带回服务端进行重新召回与排序,具体算法细节也将在后续内容中进行介绍。
端上算法模型上,我们首次在端上进行12G级别的大规模深度神经网络的推理,通过端云联合部署,使得该神经网络可以在端上进行实时预估;同时,我们还基于端智能的分布式部署能力,研发了千人千模的能力,来提升模型的个性化效果,具体算法方案见后续部分。整体的端云联合部署方案、依赖的基础服务等如下图所示。
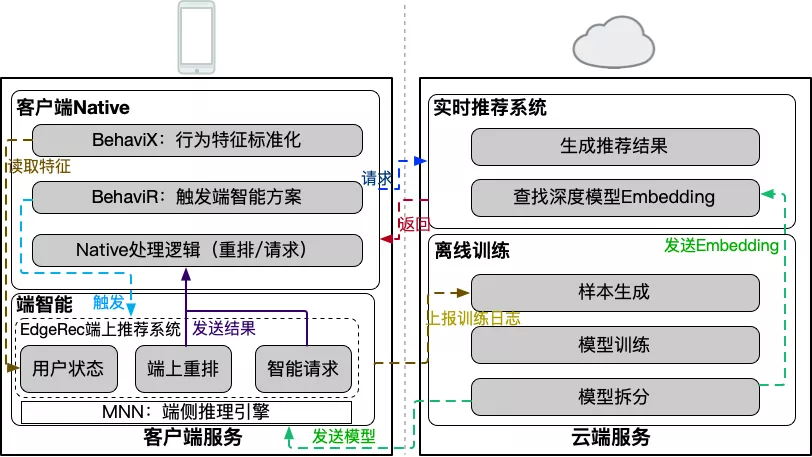
为了实现EdgeRec端上推荐系统,我们依赖了许多淘系的基础服务,其中包括:
- MNN:淘系自研轻量级端侧推理引擎 。为算法的脚本、模型和工具库提供运行环境。https://github.com/alibaba/MNN
- BehaviX:淘系全域端上用户数据中心。端侧用户数据与特征中心,定义一套方便算法使用的数据标准,提供行为本地标准化处理,为算法提供了行为、特征、样本的通用基础数据源。
- BehaviR:淘系端上智能调度框架。串联前台交互、用户感知、用户触达。对用户的实时行为调用端侧算法模型预测意图,进行本地重排、智能刷新等实时决策 。
端上重排
为什么要做端上重排
服务端决策延迟
目前,信息流推荐的分页普遍较长。以我们电商首页信息流为例,采用50一分页的分页机制,一屏展示约4个商品,用户需要划十几屏后才能发起新的请求,看到下一页的商品。长分页导致用户在刚分页时点击了某个商品之后,直到下一分页,服务端才能根据该行为下发用户可能感兴趣的相关商品。从上文不同坑位的点击率曲线可以看出,在分页刚开始时点击率最高,然后由于决策滞后,点击率逐渐下降,知道下一次分页请求决策时,点击率才回升。
服务端感知不及时、不完整
服务端对用户行为的感知依赖于行为记录、行为上报和行为解析,整体链路包含了以下问题:
- 感知不及时:服务端想要获取用户的行为,需要等待行为从用户手机端上报到服务端,然后服务端对行为加以解析,这些时间延迟导致用户的实时意图无法及时被服务端感知,在大促期间由于流量压力,这种延迟更为明显。
- 感知不完整:目前的搜索、推荐、广告算法模型如DIN、BST等,主要特征包括以商品为粒度的曝光序列、点击序列、收藏序列、加购序列、购买序列等序列。而算法模型的进一步升级需要描述某一种行为的“强与弱”。以“商品点击序列”这个行为为例,从细节来看,为了描述一次商品点击的强弱,我们需要详情页的细节行为来描述用户对这次“商品点击”的意图强弱,比如详情页各区块停留时长、各控件点击等;从上下文来看,我们需要这次点击的来源场景信息、APP来访等信息,通过上下文信息来描述一次商品点击的用户意图。而端上是对用户意图进行感知的最实时的位置。
端上行为序列建模
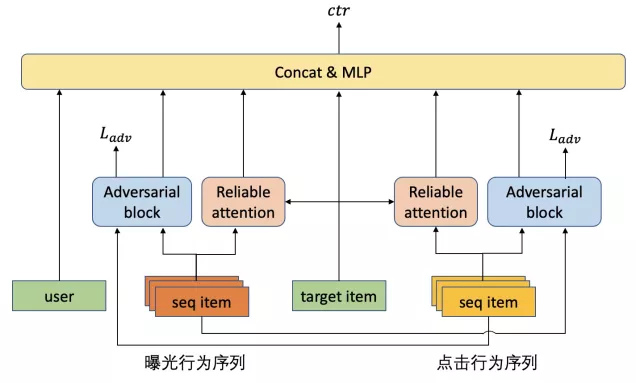
在端上重排模型中,对于用户全域行为的序列建模分为encoder和decoder两个部分,前者整体建模用户状态,可用于重排、混排和智能请求等,后者则基于重排候选商品逐一进行点击率预估,最后将排序结果展示给用户。下面分别介绍这两个模块。细节内容见我们在CIKM2020上发表的论文[1]。
RNN-based encoder。端上重排的曝光序列、点击序列等多个行为序列,首先会分别使用GRU模块进行encode,保留每一个state得到encode之后的各个序列。
Attention-based decoder。排序模型中行为序列decoder常用的target attention模型,会使用目标候选商品与行为序列中的商品计算相关性,然后对序列进行加权。目前attention-based decoder基于对各个序列进行建模时,存在两个问题:
- 每种序列行为内都存在多种细节行为,如曝光行为序列中的曝光时长、曝光次数、滚动速度和点击行为序列中的点击来源、各区块点击情况、各区块曝光时长等,这些细节信息如果只是简单的concat到行为商品信息中,无法被充分建模
- 行为序列之间割裂严重,多个序列通常在分别建模之后才在MLP阶段进行隐式交互,没有充分利用到行为与行为之间的关系。
针对以上的两个问题,我们设计了行为内的细节行为Reliable attention建模以及行为之间的序列对抗建模。整体模型架构如下图所示,Reliable attention建模以及行为之间的序列对抗建模,将在后面进行分别介绍。
行为细节建模——Reliable attention
Target attention加权方式在计算权重时只考虑到商品与商品之间的关系,没有考虑到用户在该行为中发生的行为细节。因此,我们首先实验通过noninvasive attention引入细节行为,证明了细节行为的有效性。进一步地,基于行为细节对行为的可信度刻画,我们提出了Reliable attention,对序列进行可信度加权,取得了更优的效果。下面具体介绍这两个模型
Noninvasive attention
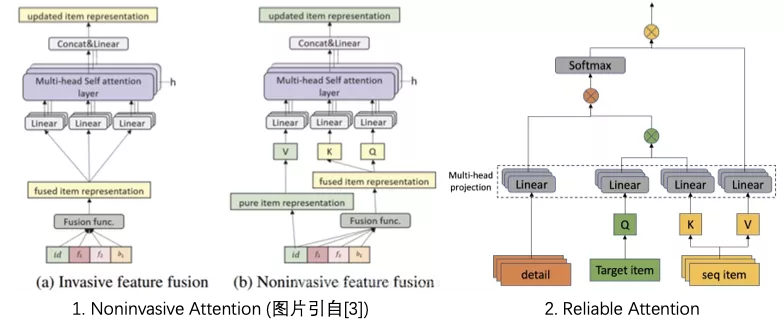
noninvasive attention论文[3]中指出,序列建模最终输出的是基于item的兴趣序列的表示,如果将side information混入到item表示中,则会对序列建模带来噪声,使得side information的收益被消减。而noninvasive(非入侵)的方式则是根据混杂了side info的item 表示来计算相似性/相关性,再用于对纯净的item representation进行加权处理,从而做到不污染序列item表示又考虑side information带来的收益。下图1表示了invasive attention与noninvasive attention两种方式的对比。
Reliable attention
Noninvasive attention的缺点在于该方法需要在序列decoder前加入一层self attention进行进一步的encode,计算消耗较大,而由于目标候选商品缺乏后验细节行为,所以直接将目标候选商品作为noninvasive attention query用于target attention decode则会出现映射空间不一致的问题。同时,item信息和细节信息fusion之后,由于部分细节信息特征空值率较高,projection输出易受item信息主导。拆分开来计算可以保证不会细节加权和item相似度计算不会互相干扰。因此我们设计了multihead reliable attention的方式,使用行为细节直接在target attention阶段进行序列可信度加权,优化target attention结果。下图2展示了reliable attention模块的计算细节。
多序列建模——序列对抗建模
目前的排序模型中为了全面建模用户的行为信息,常常使用多个行为建模从各方面建模用户,如电商排序模型中的曝光序列、点击序列、加购序列、购买序列等,行为与行为之间显然存在许多关联,因此多个序列之间的交互对于用户的兴趣建模十分重要。目前多序列建模中常见的建模方式为:
- 隐式交互。各个序列分别独立建模,然后将结果进行拼接,在最后的MLP阶段再进行隐式交互。
- Cross attention建模。以曝光序列和点击序列为例,在attention中,曝光行为序列作为query,点击行为序列作为key和value,得到曝光行为序列对点击行为序列的attention结果,再调换一下得到点击行为序列对曝光行为序列的attention结果,最后再将这两个结果进行拼接。
以上第一种隐式交互建模方式对于多序列的建模较弱,而cross attention的方式只是选择当前曝光序列与当前点击序列彼此之间相近的部分,如果当前的曝光序列与当前的点击序列关联性不强,则难以有效挖掘曝光序列中的点击成分、挖掘点击序列中的负反馈成分。
因此,我们设计了一种序列对抗的方式,来挖掘出行为之间内在的联系,从而寻找当前曝光序列当中有哪些行为是真正的负反馈,而哪些行为与点击有更相近的关系,相应地,在点击序列中寻找哪些行为是有效点击,哪些行为是无效点击。
具体地,以点击行为序列对曝光行为序列进行对抗建模为例,对抗模块(Adversarial block)网络结构如下图所示:
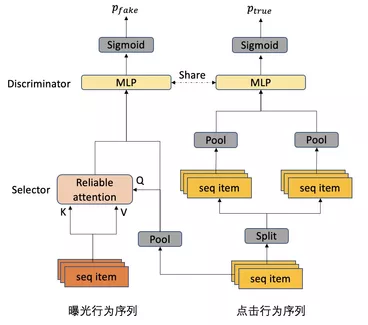
其中,Pool操作表示使用mean pooling将序列信息进行聚合;Split操作表示把点击行为序列中分割为不重叠的部分。Discriminator使用的是MLP,Discriminator将输入的两个向量进行concat,并输出两个向量来自同种行为序列的概率。
在序列对抗中,输入Discriminator的两个向量只能包含行为的item信息,不能包含细节行为的具体embedding信息,因此Selector使用的是Reliable attention,其中Query来自点击行为序列聚合后的结果,而Key和Value都来自曝光行为序列。该模块期望通过Selector选出曝光行为序列当中接近点击成分的信息,而Discriminator负责鉴别两个不同的序列是否属于同一种序列。对抗模块计算出ptrue和pfake之后,对抗loss为:
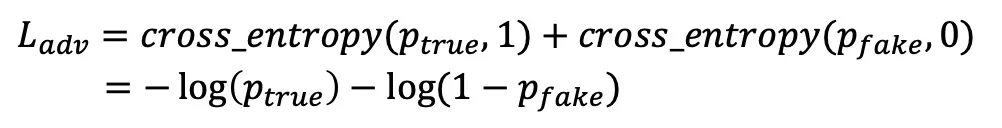
对于Selectot模块,需要最大化该对抗损失Ladv,Discriminator模块则需要最小化该对抗损失Ladv。
离线效果与线上效果
双十一期间,端上重排给我们电商首页信息流带来11%的GMV提升、12%的成交笔数提升。在端上重排模型进行端上行为序列建模优化的实验对比为
AUC | |
baseline | 0.7497 |
with noninvasive attention | 0.7501 |
with reliable attention | 0.7508 |
with reliable attention & seq adversarial block | 0.7518 |
从上表对比可以看出,在端上重排模型中加入Noninvasive attention建模细节行为,离线AUC提升较为微弱。使用Reliable attention建模细节行为,离线AUC提升为0.0011。在Reliable attention的基础上,加入序列对抗建模,离线AUC提升从0.0011变成0.0021。上线后成交笔数提升2%,GMV提升2%。
端上智能请
背景
在信息流推荐中,分页请求机制极为常见,一方面受限于网络带宽,为了减小延迟优化用户体验,另一方面为了能够留下调整推荐内容的空间,针对用户的推荐内容会被分批推送到端上。但考虑到QPS压力,一般分页的长度固定,而且不会特别小,这就带来一些问题:
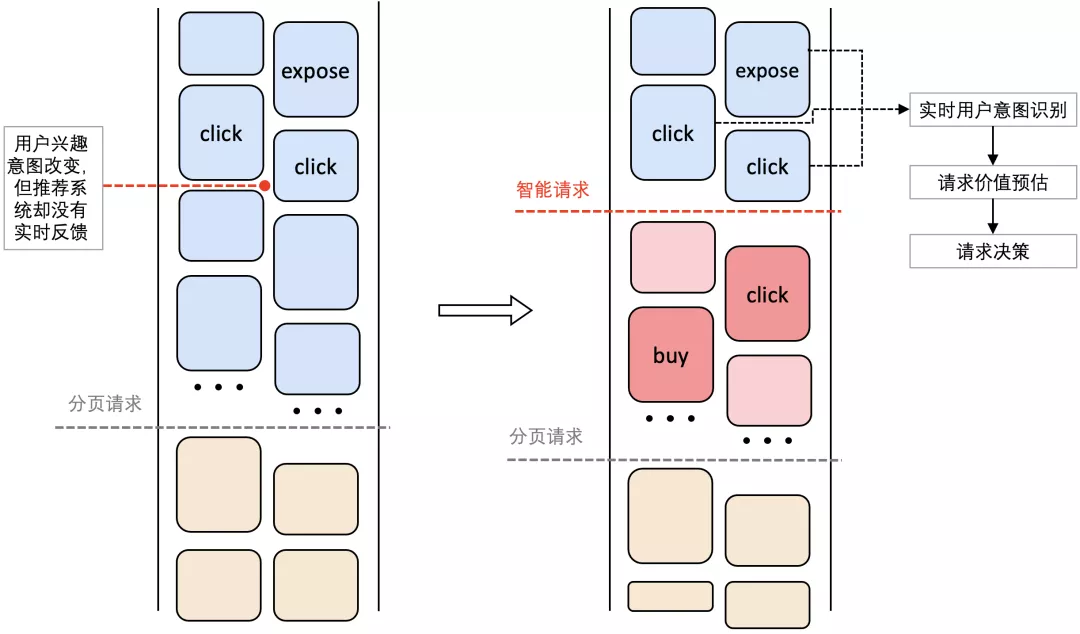
- 推荐内容更新的时机与用户意图变更的时机无法匹配。如图1所示,用户的兴趣意图和目标商品随用户浏览而变化,但分页请求导致端上商品池更新时机固定,云端的推荐内容排序无法实时的对用户需求意图改变做出反馈。
- 无法实时的对用户意图进行检测。只有实时的用户行为特征才能反映用户当下的需求。每次分页请求后,服务端可以拿到用户的行为意图特征,并基于此进行召回排序。但由于分页请求时机固定,加上网络的带宽和延迟,用户的实时行为中大量全域细节行为无法上传,导致云端推荐模型对用户意图的推测出现偏差。
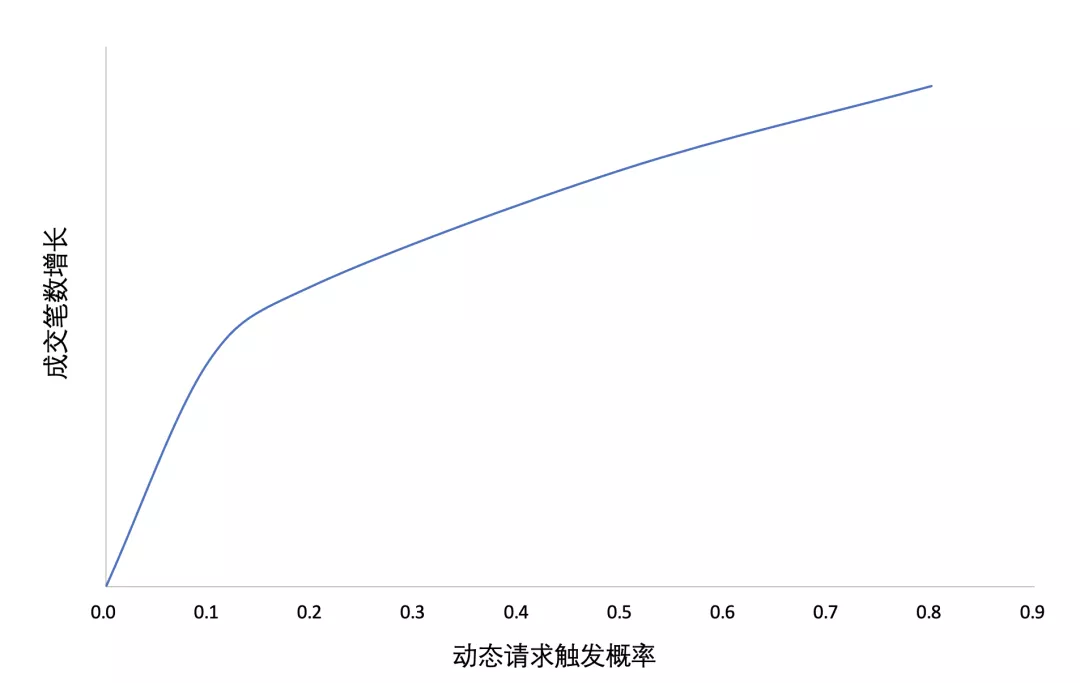
- 无法动态分配请求资源,导致大量无效请求,而且无法实时调节QPS压力。如下图,在分页请求的基础上,在每一个分页中以不同概率随机插入动态请求,随着概率的上升,用户的购买率也随之上升。由此可见更多的请求能够带来更好的推荐,导致更多的购买。由于不同用户兴趣意图变更时机不同,不同时刻对不同用户施加一次请求的产生的价值也不同,非个性化的统一分页请求会导致大量请求资源的浪费,线上效果提升与资源分配不匹配。
端上是请求的发起者和推荐内容展示终端,对用户行为有最实时的感知处理能力,因此我们希望通过端上智能请求来做个性化请求决策,提升推荐系统的实时感知和实时反馈的能力,同时预估请求价值,合理分配请求资源。
端上智能请求会检测用户在端上检测用户兴趣意图的变化,通过请求价值预估得到在当下给该用户施加请求产生价值大小,再通过请求动态规划算法来做出是否请求的决策,让请求产生真正的线上收益。如下图所示。
双11期间,在我们电商首页信息流推荐场景中,端上重排结合智能请求算法和请求价值预估模型,相比只结合动态请求规则(每页固定增加一次请求),线上成交金额提升超过3%,说明智能请求能够实时感知用户兴趣变化,在更好的时机更新端上商品池,为用户带来更好的推荐,促使购买行为的发生。
请求价值预估Request Uplift
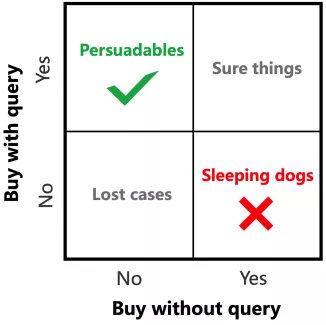
在请求价值预估中,我们使用因果推断-请求价值增益模型,来预测请求导致的购买率增益,而不是购买率本身。如下图所示,由于不同用户对请求的敏感程度有差异,只有部分用户或者在部分情况下,给与更多的请求能够使线上产生真正的收益。部分情况下用户的行为不会因请求而改变,而有一小部分情况下请求甚至会有负面影响[4][5]。所以我们用因果推断-请求价值增益模型分别建模施加请求和不施加请求下的购买率和对应的购买增益,推测出在特定情况下,由于增加请求导致的真实购买增益,来作为当前请求的价值。
请求价值预估模型![]() 会分别预测不施加智能请求下用户的购买预估
会分别预测不施加智能请求下用户的购买预估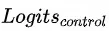 和对应的购买率
和对应的购买率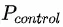 ,以及购买增益,也就是请求价值预估
,以及购买增益,也就是请求价值预估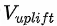 ,并同时推断出施加智能请求下用户的购买预估
,并同时推断出施加智能请求下用户的购买预估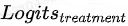 和对应的购买率
和对应的购买率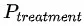 。
。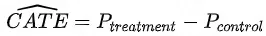 就是对
就是对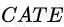
的预估,而![]() 与
与 成正相关,所以我们会直接用
成正相关,所以我们会直接用![]() 来作为请求决策的依据。
来作为请求决策的依据。
模型上分为两部分,第一部分中与端上重排模型一样需要进行行为序列建模,一方面,使用embedding table和user state模型预先处理用户在端上的行为特征![]() ,得到包括用户曝光商品特征序列
,得到包括用户曝光商品特征序列![]() ,用户历史点击商品特征序列
,用户历史点击商品特征序列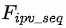 和用户实时点击商品特征序列
和用户实时点击商品特征序列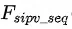 (指本次session内的点击商品特征),这三种特征。这三种特征代表了用户潜在的兴趣意图和购买倾向。另一方面,通过
(指本次session内的点击商品特征),这三种特征。这三种特征代表了用户潜在的兴趣意图和购买倾向。另一方面,通过![]() 将待重排商品池中的商品序列
将待重排商品池中的商品序列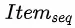 编码成特征序列
编码成特征序列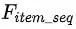 。
。
在后续的模型中,我们通过attention等操作来挖掘出重排商品池中的商品序列和用户潜在兴趣的匹配程度,当匹配程度较小,说明若此时增加一次智能请求,能带来的增益将较大。首先,我们通过self-attention和均值操作将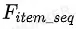 融合编码成
融合编码成![]() 。之后把
。之后把![]() 作为query,把
作为query,把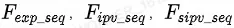 同时作为key和value,通过multi-head attention,并用求和操作将其融合编码成
同时作为key和value,通过multi-head attention,并用求和操作将其融合编码成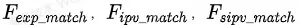 ,以此来代表商品池中的商品和用户兴趣的匹配程度。之后,
,以此来代表商品池中的商品和用户兴趣的匹配程度。之后,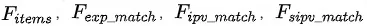 将会和上端上场景下的实时上下文
将会和上端上场景下的实时上下文![]() 并在一起,来作为模型第二部分的输入。
并在一起,来作为模型第二部分的输入。
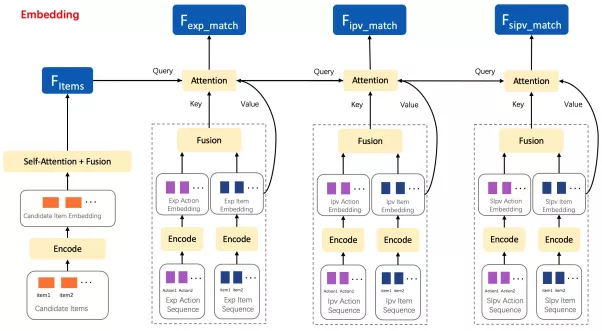
在模型第二部分中,模型第一部分的输出会被输出入到两个分支control net和uplift net中,分别用来预测不施加智能请求下用户的购买预估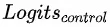 和智能请求价值预估
和智能请求价值预估![]() ,并以此来计算出对应的
,并以此来计算出对应的![]() ,
,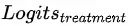 和
和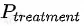 。这里,我们简单的用2个MLP来作为control net和uplift net。
。这里,我们简单的用2个MLP来作为control net和uplift net。
离线指标与线上效果
我们把模型做出是否请求的决策之后![]() 坑内是否发生购买行为作为Label。control组,treatment组和总体的AUC作为离线指标。
坑内是否发生购买行为作为Label。control组,treatment组和总体的AUC作为离线指标。
all | control | treatment |
0.79564 | 0.81003 | 0.78040 |
双11期间,端上重排[1]结合智能请求模型相比只结合智能请求规则(每页固定增加一次请求),线上成交笔数提升2%,成交金额提升3%,说明智能请求能够实时的检测用户兴趣意图变化,在更加合适的时机发起请求来更新端上商品池,为用户带来更好的推荐,刺激购买行为的发生。同时,我们将智能请求的业务效果与规则请求持平后,发现请求QPS能够降低32%,对云端计算资源缩减也有很高的价值。
智能请求模型会在更合适的时机做出施加请求的决策,促使请求之后的购买率远大于不请求。如表中所示,模型决定请求之后10坑内的购买率(%)是不请求的360%,是随机请求的259%。数据表明智能请求模型大大提高了请求之后的购买率。
无请求 | 请求(随机) | 智能请求(模型) | |
5 | 0.04816 | 0.06685 | 0.17521 |
10 | 0.09295 | 0.12935 | 0.33508 |
15 | 0.13439 | 0.18854 | 0.47695 |
20 | 0.17371 | 0.24266 | 0.83394 |
MetaFusion个性化模型融合算法
背景
“千人千面”是过去几年搜推广业务增长的关键点,如何个性化信息检索结果成为了算法的工作重点,给搜推广业务带来了巨大的业务增长。目前,“千人千面”是源自特征层面的个性化,比如普遍使用的用户历史行为特征、用户长短期统计等,而模型都是使用统一的大模型。同时,用户的行为数据会从客户端传回服务端,然后在云端训练统一的推荐模型。大模型的方式,能够很好的表达Item-to-Item、User-to-User的相关关系,在保持个性化的能力下提升模型的泛化性。
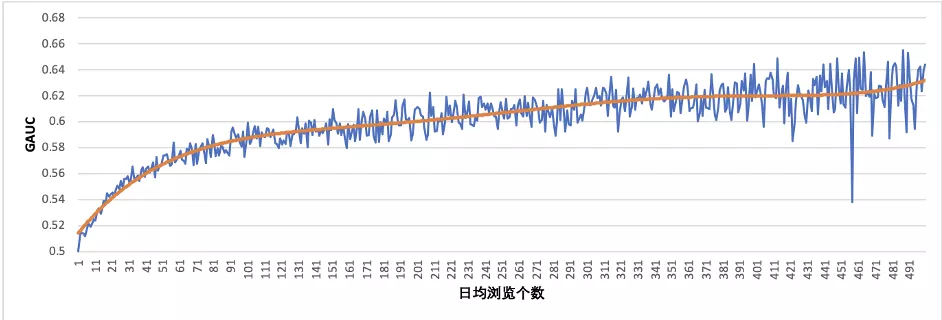
然而,这种千人一模的方式,也带来了推荐公平性的问题。目前大部分场景里,20%的高活用户贡献了80%的训练样本,这也导致了模型会更加偏向于高活用户的习惯进行推荐,从下面图中曲线可以看出,日均PV较低的用户其模型打分准度(GAUC)也较低。另外,千人一模的方式,也会有数据隐私保护的问题。因此,我们希望能为每个用户提供其个性化模型,以达到极致的个性化。
训练个人模型的难点
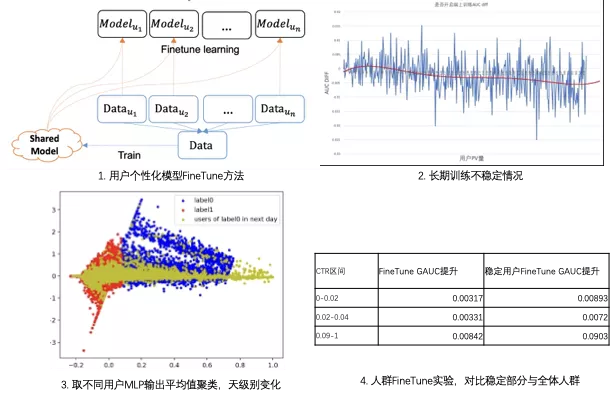
虽然个人模型有很高的研究价值,但是该工作的难点也很多。首先我们使用了最常用的方法,基于所有用户日志训练出元模型,并在单个用户日志上Finetune的方式,产出用户个性化模型,整体流程如下图1。通过该方式发现的问题有:通过该方式发现的问题有:
- 长期训练不稳定:如下图2,随着个人数据的多次训练,逐渐过拟合于用户本人局部数据,导致用户-用户的协同过滤信息缺失,最终auc反而会变差。
- 用户行为不稳定:如下图3,取第N天大模型每个人用户表征层的输出值平均值,拼成一个向量做聚类,通过Kmeans算法聚成两个类别,并通过PCA降维到两维,可视化成红色和蓝色两类。而当使用第2天蓝色部分用户的数据,继续通过该模型输出用户表征层输出值时,却发现表现为黄色部分。即不同天之间用户的行为有很大的变化。为了验证该问题,我们取了不同Ctr区间的人群,使用N-1天全人群大模型做Meta Model,并使用单独人群第N天数据做FineTune得到FineTune Model,验证FineTune模型对比MetaModel的在N+2天数据上评估的提升。并分别对比该人群全部用户和稳定用户(第N+2天用户Ctr仍在该区间内)的效果,整体。结果如下图4,发现稳定用户部分的提升,相比全部用户部分,GAUC提升会高出不少。而这块也是用户个性化模型的增长空间。
MetaFusion个性化模型融合算法
为了解决以上提出的两个问题,我们提出了MetaFusion框架和相应的算法,其中框架如下图所示:
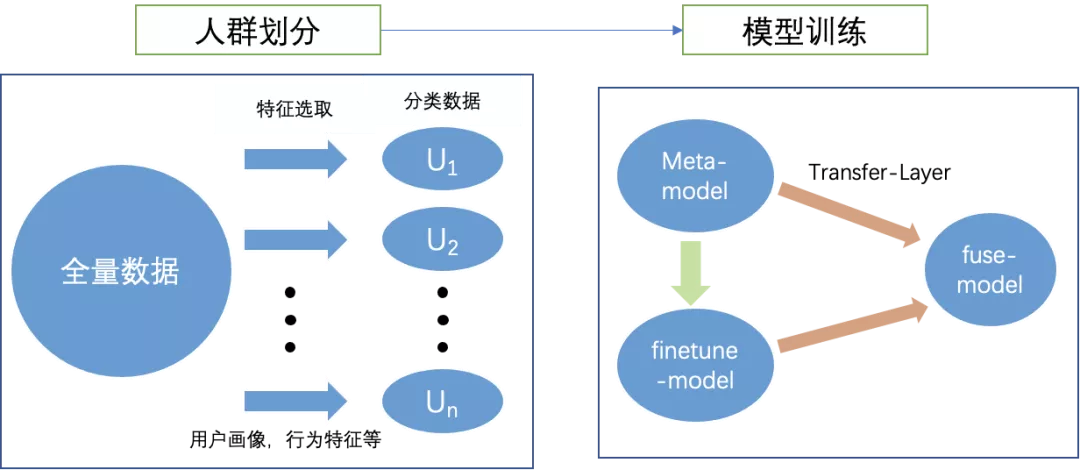
为了解决单人数据训练过拟合的问题,我们决定使用人群来训练人群的FineTune模型,通过将单个用户扩大到用户群体,可以一定程度解决训练样本稀少和数据不均衡问题,对于人群的划分,其目标同个性化模型FineTune类似,是为了缓解在推荐中高活用户的主导现象,同时也旨在为存在冲突性行为的不同用户建立更加个性化的推荐模型。
为了解决用户行为不稳定的问题,我们根据用户自身信息来做Meta模型和FineTune模型的个性化融合,识别用户的不稳定程度,并对两个模型进行融合。其原因是,即使在分类人群的数据样本Ui上训练拟合了,但Ui在后一天的数据上的特征可能已经变化了(即有一部分用户已经不在之前划分的区间标准内了),如5.2部分的图3所示,因此依旧用拟合训练集的模型不一定有效,需要学习用户特征的变化情况来提高分类模型的稳定性。
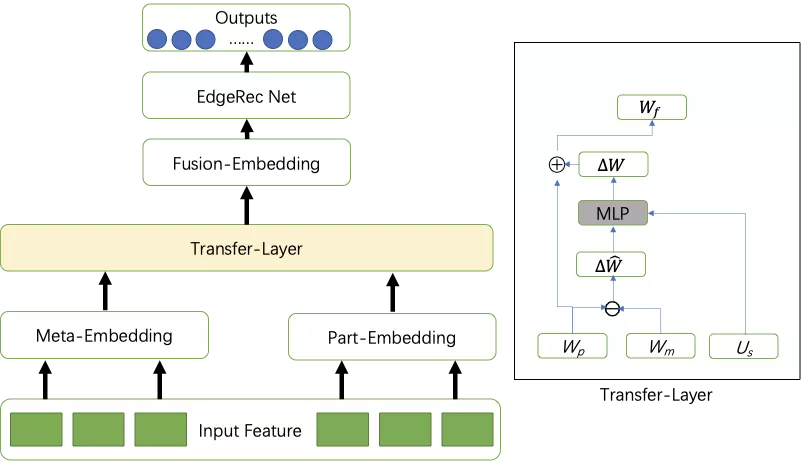
在原有全量数据的基础上,我们可以得到集中元模型,其模型参数用Wm表示,对于每一个人群而言,我们利用其对应部分的第T天的数据作为训练集样本,T+1天的数据作为测试集。在训练集上得到模型参数Wp,该模型我们认为其拟合第T天的用户行为,为了使模型在T+1天保持有一定的稳定性,引入了Transfer-Layer,并结合用户稳定性统计特征Us,融合Wp和Wm的模型参数,学习Wp和Wm的模型变化和用户稳定性统计特征之间的关系,最终融合出Wf。我们认为Transfer Layer是有更高的泛化性的,能支持多天之间的用户状态变化。模型结构如下图所示。
离线效果上如下表,可以看到MetaFusion后,GAUC提升比单独Finetune后都有相应的提升。可以认为“稳定用户FineTune GAUC提升”是用户个性化模型的能力上限,Meta-Fusion后的确向该值逼近了一些。我们将通过Meta-Fusion产生的用户个性化模型利用端智能的分离部署能力,部署在了用户个人手机上。在线效果上,在不同人群上普遍有2%的Ctr和点击量的提升。
CTR区间 | FineTune GAUC提升 | 稳定用户FineTune GAUC提升 | Meta-Fusion Model GAUC提升 |
0-0.02 | 0.00317 | 0.00893 | 0.00567 |
0.02-0.04 | 0.00331 | 0.0072 | 0.00423 |
0.09-1 | 0.00842 | 0.00903 | 0.00875 |
总结
EdgeRec建设的三年内,每一年都有新进展,双十一GMV提升从19年的+5%,到20年的+8%,到今年的+13%,每年都展现了其巨大的增长空间,成为推荐系统中不可或缺的系统。截至目前,端上推荐系统体系的潜力做了一定兑现。接下来,端智能需要与云上算法做端云算法间的协同,端上发挥其信息量大、信息实时的优势,云端发挥其候选存储空间更大的优点,通过端云协同提升业务效果。
参考文献
[1] Gong Y, Jiang Z, Feng Y, et al. EdgeRec: recommender system on edge in Mobile Taobao[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2477-2484.
[2] Chen, Fei, et al. "Federated meta-learning for recommendation." arXiv preprint arXiv:1802.07876 (2018).
[3] Liu C, Li X, Cai G, et al. Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation[J]. arXiv preprint arXiv:2103.03578, 2021.
[4] Gutierrez, Pierre, and Jean-Yves Gérardy. "Causal inference and uplift modelling: A review of the literature." International Conference on Predictive Applications and APIs. PMLR, 2017.
[5] Künzel, Sören R., et al. "Metalearners for estimating heterogeneous treatment effects using machine learning." Proceedings of the national academy of sciences 116.10 (2019): 4156-4165.
[6] Goldenberg, Dmitri, et al. "Free Lunch! Retrospective Uplift Modeling for Dynamic Promotions Recommendation within ROI Constraints." Fourteenth ACM Conference on Recommender Systems. 2020.





