

这篇文章酝酿了很久,一直想写,却一直觉得似乎要讲的东西有点杂,又不是很容易讲清楚,又怕争议的地方很多,就一拖再拖。但是,每次看到不少遇到跟这个设计相关导致的问题,又忍不住跟人讨论,但又很难一次说清楚,于是总后悔没有及早把自己的观点写成文章。不管怎样,观点还是要表达的,无论对错。
故障的推手——“Result"
先说结论:接口方法,尤其是对外HSF(开源版本即dubbo) api,接口异常建议不要使用Result,而应该使用异常。阿里内部的java编码,已经习惯性对外API一股脑儿使用“Result”设计——这是导致许多故障的重要原因!
一个简化的例子
// 用户查询的HSF服务API,使用了Result做为返回结果
public interface UserService {
Result<User> getUserById(Long userId);
}// 一段客户端应用facade的调用示例。读写缓存逻辑部分省略,仅做示意
public User testGetUser(Long userId) {
String userKey = "userId-" + userId;
// 先查缓存,如果命中则返回缓存中的user
// cacheManager.get(123, userKey);
// ...
try{
Result<User> result = userService.getUserById(userId);
if (result.isSuccess()) {
cacheManager.put(123, userKey, result.getData());
return result.getData();
}
// 否则缓存空对象,代表用户不存在
cacheManager.put(123, userKey, NullCacheObject.getInstance(), 3600);
return null;
} catch (Exception e) {
// TODO log
throw new DemoException("getUserById error. userId=" + userId, e);
}
}上面的代码很简单,客户端应用对User查询服务做了个缓存。有些同学可能一眼就看出来,这里隐藏的bug:第10行的“result.isSuccess()”为false的实际含义是什么?是服务端系统异常吗?还是用户不存在?光看API是很难确定的。不得不去找服务提供方或文档确认其逻辑,根据错误码进行区分。如果是服务端系统异常,那么第15行将导致线上bug,因为后续1小时对该用户的请求都认为用户不存在了。
严谨点的写法
如果要写正确逻辑,那么代码可能会变成这样:
public User testGetUser(Long userId) {
String userKey = "userId-" + userId;
// 先查缓存,如果命中则返回缓存中的user
// cacheManager.get(123, userKey);
// ...
try{
Result<User> result = userService.getUserById(userId);
if (result.isSuccess()) {
cacheManager.put(123, userKey, result.getData());
return result.getData();
}
if ("USER_NOT_FOUND".equals(result.getCode())) {
// 否则缓存空对象,代表用户不存在
cacheManager.put(123, userKey, NullCacheObject.getInstance(), 3600);
} else {
// 可能是SYSTEM_ERROR、DB_ERROR等一些系统性的异常,TODO log
throw new DemoException("getUserById error. userId=" + userId + ", result=" + result);
}
} catch (DemoException e) {
throw e;
} catch (Exception e) {
// TODO log
throw new DemoException("getUserById error. userId=" + userId, e);
}
return null;
}很显然,代码变得复杂起来了,加上对外部调用的try catch异常处理,实际代码变相当复杂繁琐。
不使用Result的例子
public interface UserService {
User getUserById(Long userId) throws DemoAppException;
}public User testGetUser(Long userId) {
String userKey = "userId-" + userId;
// 先查缓存,如果命中则返回缓存中的user
// cacheManager.get(123, userKey);
// ...
try {
User user = userService.getUserById(userId);
if (user != null) {
cacheManager.put(123, userKey, user);
return user;
} else {
// 否则缓存空对象,代表用户不存在
cacheManager.put(123, userKey, NullCacheObject.getInstance(), 3600);
return null;
}
} catch (Exception e) {
// TODO log
throw new DemoException("getUserById error. userId=" + userId, e);
}
}这样一看,代码简洁清晰很多,也更符合对普通API的调用习惯。
使用Result的几个问题
- 调用成本高:虽然通过对依赖的API深入了解异常设计,可以写出严谨的代码以避免出现bug,但是简单的逻辑,代码却变得复杂。换言之,调用的成本变高。但是很可惜,我们忘记判断而写成“一个简化的例子”这样是往往常事。
- 无意义错误码:SYSTEM_ERROR、DB_ERROR等系统异常的错误码,虽然放在Result中了,但是调用方除了日志和监控作用外,业务逻辑永远不会关心,也永远处理不了。而些错误码的处理分支,实际与抛异常的处理逻辑一样。既然如此,为何要将这些错误码放在返回值里?
关于阿里巴巴开发规约
我们看《阿里巴巴Java开发手册》的“异常处理”小节第13条:
【推荐】对于公司外的http/api开放接口必须使用“错误码”;跨应用间HSF调用优先考虑使用Result方式,封装isSuccess()方法、“错误码”、“错误简短信息”;而应用内部推荐异常抛出。
这条推荐非常具有误导性,在2016年孤尽对于这条规范进行调研时的帖子:《【开发规约热议投票02】HSF服务接口定义时,是Result+isSuccess方式返回,还是是抛异常的方式?》有部分同学不建议使用Result,但大部分同学推荐了Result的做法。
为什么说这条规约具有误导性?
因为这个问题本身没有讲清楚“对什么东西的处理”要用Result还是异常的方式,即这里没有讲清楚我们要解决的问题是什么。事实上我们常说的“失败”,往往混淆了2种含义:
- 系统异常:比如网络超时、DB异常、缓存超时等,调用方一般不太可能基于这些错误类型做不同的业务逻辑,常用用于日志和监控,方便定位排查。
- 业务状态:比如业务规则拦截导致的失败,比如发权益时库存不足、用户限领等,为方便后文叙述和理解,暂时称为“业务失败”。这类“失败”,从机器层面来看,严格来说不能算做是失败,这只是一种正常的业务结果,这和“调用成功”这个业务结果对系统来说没有任何区别,只是一个业务状态而已。调用方往往可能关心对应的错误码,以完成不同的业务逻辑。
有经验的开发,都会意识到这2种含义的区别,这对于帮助我们理解接口的异常设计非常重要!对这条开发规约而言,如果是第2种,并没有什么大的问题,但如果是第1种,我则持相反的意见,因为这违背了java语言的基本设计,不符合java编码直觉,会潜移默化造成前面案例所示的理解和使用成本的问题。

为什么针对HSF?
当我们讨论要用Result代替Exception时,经常会以这是HSF接口为由,因为性能开销等等。我们常说HSF这种RPC框架,设计的目的就是为了看起来像本地调用。那么,这个“看起来像本地调用”到底指的是哪方面像呢?显然,编码时像,运行时不像。所以我们写调用HSF接口的代码时,感觉像在调用本地方法,那么我们的编码直觉和习惯也都应该是符合java的规范的。因此,至少有几点理由,对于系统异常,我们的HSF接口更应该使用Exception,而非Result的方式:
- 只有同样遵循本地方法调用的设计,来设计HSF的api,才能更好做到“像本地调用一样”,更符合HSF设计的初衷。
- HSF接口是往往用于对外部团队提供服务,更应该遵循java语法的设计,提供清晰的接口语义,降低调用方的使用成本,减少出bug的概率。
- Result并无统一规范,而Exception则是语言标准,有利于中间件、框架代码的监控发现和异常重试等逻辑生效。
当然,由于“运行时不像”,对于HSF封装带来的抽象泄露,我们在使用异常时,需要关注几点问题:
- 异常要在接口显式声明,否则客户端可能会反序列化失败。
- 尽可能不带原始堆栈,否则客户端也可能反序列化失败,或者堆栈过大导致性能问题。可以考虑异常中定义错误码以方便定位问题。
结论
无论是HSF接口,还是内部的API,都应该遵循java语言的编码直觉和习惯,业务结果(无论成功还是失败)都应该通过返回值返回,而系统异常,则应该使用抛出Exception的方式来实现。
关于Checked Exception
讲到这里,我们发现,java的Checked Exception的设计,作用上和反映业务失败的Result很像。Result是强制调用方进行判断和识别,并根据不同的错误码进行判断和处理。而Checked Exception也是强制调用方进行处理,并且可能要对不同的异常做不同的处理。但是,基于前面的结论,业务失败应该通过返回值来表达,而不是异常;而异常是不应该用于做业务逻辑判断的,那么java的Checked Exception就变成奇怪的存在了。这里我明确我的观点,我们应该尽可能不使用Checked Exception。另外,《Thinking in Java》的作者 Bruce Eckel就曾经公开表示,Java语言中的Checked Exception是一个错误的决定,Java应该移除它。C#之父Anders Hejlsberg也认同这个观点,因此C#中是没有Checked Exception的。
Reselt 的实质是什么?

我们看看一个java方法的签名(省略修饰符部分):
- 方法名:用于表达这个方法的功能
- 参数:方法的输入
- 返回值类型:方法的输出
- 异常:方法中意外出现的错误
所以,返回值和方法功能必须是配套的,返回值类型,就是这个方法的功能执行结果的准确表达,即返回值必须正好就是当前这个方法要做的事情的结果,必须满足这个方法语义,而不应该有超出这个语义外的东西存在。而异常,所说的“意外”,则是指超出这个方法语义之外的部分。这几句话有点拗口,举个例子来说,上面这个用户接口,语义就是要通过用户id查询用户,那么当服务端发生DB超时错误时,对于“通过用户id查询用户”这个语义来说,“DB超时错误”没有任何意义,使用异常是恰好合适的,如果我们把这个错误做为错误码放在返回值的Result里,那么就是增加了这个方法的使用成本。
Result的由来
到底为什么会有“Result”这样的东西诞生呢?如果设计的方法返回值是Result类型,那么它必须能准确反应这个方法调用的结果。实际上,以上面的例子为例,这个时候的Result就是User类本身,User.status相当于Result.code。这听起来可能有点和直觉不符,这是为什么?
public class UserRegisterResult {
private String errorCode;
private String errorMsg;
private Long userId;
// ...
public boolean isSuccess() {
return errorCode == null;
}
// ...
}UserRegisterResult registerUser(User user) throws DemoAppException;
我们再来看看上面这个“注册用户”的方法声明,会发现,这个方法定义一个Result显得很合适。这是因为前一个例子,我们的方法是一个查询方法,返回值刚好可以用领域对象类型本身,而这个“注册用户”的方法,显然没有现成合适的类型可以使用,所以就需要定义一个新的类型来表达方法的执行结果。看到这里,我们会以为,对于“写”与“读”类型的方法有所差异,但实际上,对于java语言或者机器来说,并无二致,第二个方法UserRegisterResult的和第一个方法的User是同等地位。所以,最重要的还是一点:需要有一个合适的类型,做为返回值,用于准确表达方法执行的功能结果。而偏“写”类型,或者带业务校验的读接口,往往因为没有现成的类型可用,为了方便,常常会使用Result来代替。
是否有必要统一Result?
讲到这里,想想,当我们这种“需要Result”的方法有多个时,我们会说“我需要一个统一的Result类”时,实际上说的什么呢?
- 我希望各种接口方法都统一同样的Result,方便使用
- 我希望有个类复用errorCode、errorMsg以及相关的getter/setter等代码
显然,第1点理由经不起推敲,为何“统一就方便使用”了?如果各种方法返回类型都一样,那就违背了“返回值要和方法功能配套”的结论,也不符合高内聚的设计原则。恰相反,返回值越是设计得专用,对调用方来说理解和使用成本越低。所以,我们实际想要的,仅仅是如何“偷懒”,也就是第2点理由。所以我们真正要做的是,只是在当前领域范围内,如何既满足让每个方法返回值专用以便使用,同时又可以偷懒复用部分代码即可。因此,绝不必要求大家都统一使用同一个Result类型。
接口返回设计建议
根据前文的结论,我们知道,对于接口方法的返回值和异常处理,最重要的是需要遵循方法的语义进行设计。以下是我梳理的一些设计上的原则和建议。
对响应合理分类
接口响应按有业务结果和未知业务结果分类,业务结果不管是业务成功还是业务规则导致的失败,都通过返回值返回;未知结果一般是系统性的异常导致,不要通过返回值错误码表达,而是通过抛出异常来表达。这里最关键一点,就是如何理解和区分某个“失败”是属于业务失败,还是属于系统异常。由于有时候这个区分并不是很容易,我们可以有一个比较简单的判断标准来确定:
- 如果一个错误,调用方只能通过人工介入的方式才能恢复,比如修改代码、改配置,或数据订正等处理,则必然属于异常
- 如果调用方无法使用代码逻辑处理消化使得自动恢复,而是只能通过重试的方式,依赖下游的恢复才能恢复,则属于异常
找到合适的场景
普通查询接口,如无必要,不要使用Result包装返回值。可以简单分为3类做为参考:
普通读接口
查询结果即是领域对象,无其他业务规则导致的失败:建议直接用领域对象类型做为返回值。如:
User getUserById(Long userId) throws DemoAppException;
写接口
或者带业务规则的读接口:
- 理想情况是专门封装一个返回值类,以降低调用方的使用成本。
- 可考虑将返回值类继承Result,以复用errorCode和errorMsg等代码,减轻开发工作量。但注意这不是必要的。
- 将本方法的错误码,直接定义到这个返回值类上(高内聚原则)。
- 若有多个方法有共同的错误码,可以考虑通过将这部分错误码定义到一个Interface中,然后实现该接口。
// UserRegisterResult、UserUpdateResult可以继承Result类,减少工作量,但调用方不需要感知Result类的存在 UserRegisterResult registerUser(User user) throws DemoAppException; UserUpdateResult updateUser(User user) throws DemoAppException;
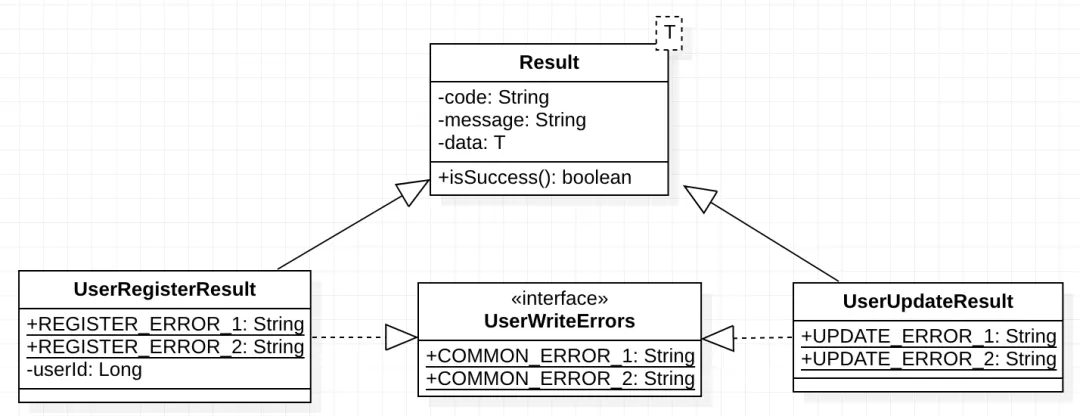
带业务规则的的领域对象读接口
完全遵循上面第2点,会给方法提供者带来一定的开发成本,权衡情况下可以考虑,套Result包装领域对象做为返回值。注意,对外不建议,可考虑用于内部方法。如下接口,“没有权限”是一个正常的业务失败,调用方可能会判断并做一定的业务逻辑处理:
// 查询有效用户,如果用户存在但状态非有效状态则返回“用户状态错误”的错误码,如果不存在则返回null Result<User> getEffectiveUserWithStatusCheck(Long userId) throws DemoAppException;
内外部区分
对外接口,尤其是HSF,由于变更成本高,更要遵循前面的原则;内部方法,方法众多,如果完全遵循需要编码成本,这里需要做权衡,根据代码规模和发展阶段不断重构和调整即可。
避免直接包装原生类型
我们对外的接口,返回值要避免出现直接使用Result包装一个原生类型。比如:
Result<Long> registerUser(User user) throws DemoAppException;
这样设计导致的结果是,扩展性很差。如果registerUser方法需要增加返回除了userId以外的其他字段时,就面临几个选择:
- 让Result支持扩展参数,通过map来传递额外字段:可读性和使用成本很高
- 开发一个新的registerUser方法:显然,成本很高
避免所有错误码定义在一个类中
有人建议,做一个全局的错误码定义,以做统一,方便排查和定位。但这样做真的方便吗?这样做实际上有几个问题:
- 完全违背了高内聚、低耦合的设计原则。这个“统一的定义”将与各个域都有耦合,同时对于某单个接口而言,则不够内聚。
- 这个统一定义的错误码,一定会爆炸式增长,即便我们对其进行分类(非常依赖人的经验),迟早也会变得难以维护和理解。
- 不要将系统异常类的错误码和业务失败错误码放在一起,这点其实和方法响应分类设计是一回事。
我们在设计拉菲2权益平台的错误码时,就犯了这样的错误。现在这个“统一的”错误码已经超过400个,揉合了管理域、投发放域、离线域等各种不同域的业务失败、系统异常的错误码,不要说调用方,即便我们自己,也梳理不清楚了。而实际上,每个域、每个方法自己的业务失败是非常有限的,它的增长一定是随着业务需求本身的变化而增长的。现在如果有个业务方来问我,拉菲2的发放接口,有哪些错误码(这问的实际是业务失败,他也只关心业务失败),我几乎难以回答。很可惜,这块目前即便重构,难度也很大。
异常处理机制
异常错误码
前面我们讲到,即便是抛异常的形式,我们也可以为我们的异常类设计错误码,异常错误码的增加会很快,往往也和当前业务语义无关,因此千万不要和业务失败的错误码定义在一起。异常内的错误码主要用于日志、监控等,核心原则就是,要方便定位问题。
避免层层try catch
到处充满异常处理的代码,会导致整个程序可读性变差,写起来也非常繁琐,可以遵循一定的原则:
- 在原始发生错误的地方try catch,比如调用HSF接口的Facade层代码,主要目的是为了记录原始的错误以及出入参,方便定位问题,一般会打日志,并转换成本应用的异常类上抛
- 在应用的最顶层catch异常,打印统一日志,并根据“为什么针对HSF?”小节中的建议,处理成合适的异常后再抛出。对于HSF接口,可以直接实现HSF的“ServerFilter”来统一在框架层面处理。
- 中间层的代码,不必再层层catch,比如domain层,可以让代码逻辑更加清晰。
参数错误
抛异常的场景,除了前面说的系统性异常外,参数错误也推荐使用异常。原因如下:
- 参数正确一般是我们当前上下文执行的前提条件,我们一般可以使用assert来保证其正确。即我们的后续逻辑是认为,当前的参数是不可能错误的,我们没必要为此写过多繁琐的防御性代码。
- 一旦发生参数错误,则一定是调用方有代码bug,或者配置bug,应该通过抛出异常的方式,充分提前在开发或测试阶段暴露。
- 参数错误对调用方来说,是无法处理的,程序不可能自动恢复,一定是会需要人工介入才可能恢复,调用方不可能会“判断如果是xx参数错误,我就做某个业务逻辑”这样的代码,因此通过返回值定义参数错误码没有意义。
系统异常和业务结果转换
系统性异常并非一定是异常,因为有些层可能有能力处理某些异常,比如对于弱依赖的接口,异常是可以吞掉,转换成一个业务结果;相反,有些接口返回的一些业务失败,但调用方认为该业务失败不可能出现,出现也无法处理,那么这一层可以将其转换成异常。
结尾
前面讲了接口的响应,包括返回值Result和异常抛出的设计,有很多结论是与现在公司内部大家常见做法是不同的,这也是我为什么特别想要表达的,有可能正是日常我们的这些习以为常做法,才导致了团队间接口依赖调用的成本提高,也是导致故障的一个很重要原因。当然,我相信,我的观点也不一定都是对的,很多同学并不一定同意上面所有的结论,所以,欢迎大家在文章下面讨论!





