

有网友提问:各种机器学习算法的应用场景分别是什么(比如朴素贝叶斯、决策树、K 近邻、SVM、逻辑回归最大熵模型)?
这些在一般工作中分别用到的频率多大?一般用途是什么?需要注意什么?
根据问题,核心关键词是基础算法和应用场景,比较担忧的点是这些基础算法能否学有所用?毕竟,上述算法是大家一上来就接触的,书架上可能还放着几本充满情怀的《数据挖掘导论》《模式分类》等经典书籍,但又对在深度学习时代基础算法是否有立足之地抱有担忧。
网上已经有很多内容解答了经典算法的基本思路和理论上的应用场景,这些场景更像是模型的适用范围,这与工业界算法实际落地中的场景其实有很大区别。
从工业界的角度看,业务价值才是衡量算法优劣的金钥匙,而业务场景往往包含业务目标、约束条件和实现成本。如果我们只看目标,那么前沿的算法往往占据主导,可如果我们需兼顾算法运行复杂度、快速迭代试错、各种强加的业务限制等,经典算法往往更好用,因而就占据了一席之地。
针对这个问题,淘系技术算法工程师感知同学写出本文详细解答。
在实际业务价值中,算法模型的影响面大致是10%
在工业界,算法从想法到落地,你不是一个人在战斗。我以推荐算法为例,假设我们现在接到的任务是支持某频道页feeds流的推荐。我们首先应该意识到对业务来说,模型的影响面大致是10%,其他几个重要影响因子是产品设计(40%)、数据(30%)、领域知识的表示和建模(20%)。
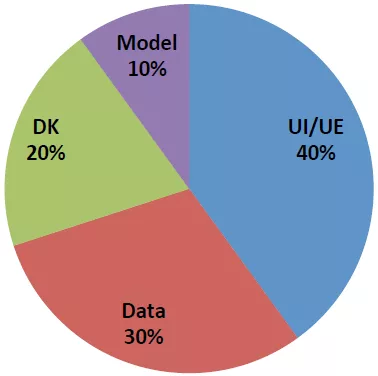
这意味着,你把普通的LR模型升级成深度模型,即使提升20%,可能对业务的贡献大致只有2%。当然,2%也不少,只是这个折扣打的让人脑壳疼。
当然,上面的比例划分并不是一成不变的,在阿里推荐算法元年也就是2015年起,个性化推荐往往对标运营规则,你要是不提升个20%都不好意思跟人打招呼。那么一个算法工程师的日常除了接需求,就是做优化:业务给我输入日志、特征和优化目标,剩下的事情就交给我吭哧吭哧。
可随着一年年的水涨船高,大家所用模型自然也越来越复杂,从LR->FTRL->WDL->DeepFM->MMOE,大家也都沿着前辈们躺过的路径一步步走下去。这时候你要是问谁还在用LR或是普通的决策树,那确实会得到一个尴尬的笑容。
但渐渐的,大家也意识到了,模型优化终究是一个边际收益递减的事情。当我们把业务方屏蔽在外面而只在一个密闭空间中优化,天花板就已经注定。于是渐渐的,淘系的推荐慢慢进入第二阶段,算法和业务共建阶段。业务需求和算法优化虽然还是分开走,但已经开始有融合的地方。
集团对算法工程师的要求也在改变:一个高大上的深度模型,如果不能说清楚业务价值,或带来特别明显提升,那么只能认为是自嗨式的闭门造车。这时,一个优秀的算法工程师,需要熟悉业务,通过和业务反复交流中,能够弄清楚业务痛点。
注意,业务方甚至可能当局者迷,会提出既要又要还要的需求给你,而你需要真正聚焦到那个最值得做的问题上。然后,才是对问题的算法描述。做到这一步你会发现,并不是你来定哪个模型牛逼,而是跟着问题走来选择模型。这个模型的第一版极大可能是一个经典算法,因为,你要尽快跑通链路,快速验证你的这个idea是有效的。后面的模型迭代提升,只是时间问题。
经典算法在淘系的应用场景示例:TF-IDF、K近邻、朴素贝叶斯、逻辑回归等
因而现阶段,在淘系的大多数场景中,并不是算法来驱动业务,而是配合业务一起来完成增长。一个只懂技术的算法工程师,最多只能拿到那10%的满分。为了让大家有体感,这里再举几个小例子:
比如业务问题是对用户进行人群打标,人群包括钓鱼控、豆蔻少女、耳机发烧友、男神style等。在实操中我们不仅需考虑用户年龄、性别、购买力等属性,还需考虑用户在淘系的长期行为,从而得到一个多分类任务。如果模型所用的的特征是按月访问频次,那么豆蔻少女很可能网罗非常多的用户,因为女装是淘系行为频次最多的类目。
比如,某用户对耳机发烧友和豆蔻少女一个月内都有4次访问,假设耳机发烧友人均访问次数是3.2次,而豆蔻少女是4.8次,那么可知该用户对耳机发烧友的偏好分应更高。因此,模型特征不仅应该使用用户对该人群的绝对行为频次,还需参照大盘的水位给出相对行为频次。
这时,入选吴军老师《数学之美》的TF-IDF算法就派上用场了。通过引入TF-IDF构建特征,可以显著提高人群标签的模型效果,而TF-IDF则是非常基础的文本分类算法。
在淘系推荐场景,提升feeds流的点击率或转化率往往是一个常见场景。可业务总会给你惊喜:比如商品的库存只有一件(阿里拍卖),比如推荐的商品大多是新品(天猫新品),比如通过小样来吸引用户复购正品,这些用户大多是第一次来(天猫U先),或者是在提升效率的同时还需兼顾类目丰富度(很多场景)。
在上述不同业务约束背景,才是我们真实面对的应用场景。面对这种情况首先是定方向,比如在阿里拍卖中的问题可描述为“如何在浅库存约束下进行个性化推荐”。假如你判断这是一个流量调控问题,就需要列出优化目标和约束条件,并调研如何用拉格朗日乘子法求解。重要的是,最终的结果还需要和个性化推荐系统结合。详见:阿里拍卖全链路导购策略首次揭秘。
面对上述应用场景,你需明白你的战略目标是证明浅库存约束下的推荐是一个流量调控问题,并可以快速验证拿到效果。采用一个成熟经典的方法先快速落地实验,后续再逐步迭代是明智的选择。
又比如,K近邻算法似乎能简单到能用一张图或一句话来描述。可它在解决正负样本不均衡问题中就能派上用场。上采样是说通过将少数类(往往是正样本)的数据复制多份,但上采样后存在重复数据集可能会导致过拟合。过拟合的一种原因是在局部范围正负样本比例存在差异,如下图所示:
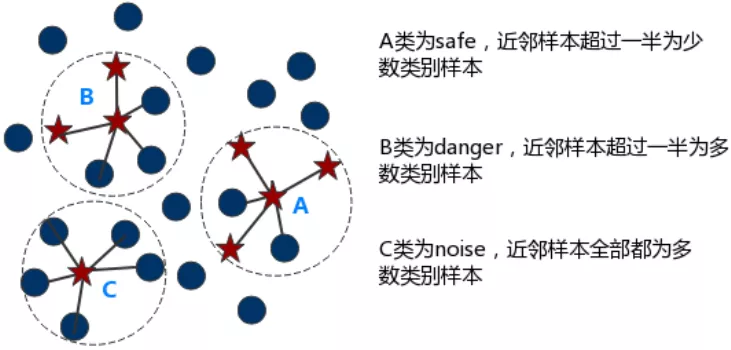
我们只需对C类局部样本进行上采样,这其中就运用到了K近邻算法。本例中的经典算法虽然只是链路的一部分,甚至只是配角儿,但离了它不行。
朴素贝叶斯虽然简单了点,但贝叶斯理论往后的发展,包括贝叶斯网络、因果图就不那么simple了。比如不论是金融业务中的LR评分卡模型,或是推荐算法精排中的深度模型,交叉特征往往由人工经验配置,这甚至是算法最不自动的一个环节。
使用贝叶斯网络中的structure learning,并结合业务输入的行业知识,构建出贝叶斯概率图,并从中发现相关特征做交叉,会比人工配置带来一定提升,也具有更好的可解释性。这就是把业务领域知识和算法模型结合的一个很好的例子。可如果贝叶斯理论不扎实,很难走到这一步。
不论深度学习怎么火,LR都是大多场景的一个backup。比如在双十一大促投放场景中,如果在0:00~0:30这样的峰值期,所有场景都走深度模型,机器资源肯定不足,这时候就需要做好一个使用LR或FTRL的降级预案。
如何成为业界优秀的算法工程师?
在淘系,算法并不是孤立的存在,算法工程师也不只是一个闭关的剑客。怎么切中业务痛点,快速验证你的idea,怎么进行合适的算法选型,这要求你有很好的算法基本功,以及较广的算法视野。一个模型无论搞的多复杂最终的回答都是业务价值,一个有良好基本功、具备快速学习能力,且善于发掘业务价值的算法工程师,将有很大成长空间。
好吧,假设上面就是我们的职业目标,可怎么实现呢。元(ye)芳(jie),你怎么看?其实只有一个句话,理论和实践相结合。
理论
对算法基本思路的了解,查查知乎你可能只需要20分钟,可你忘记它可能也只需要2周。这里的理论是你从内而外对这个算法的感悟,比如说到决策树,你脑海里好像就能模拟出它的信息增益计算、特征选择、节点分裂的过程,知道它的优和劣。最终,都是为了在实践中能快速识别出它就是最适合解决当前问题的模型。
基本功弄扎实是一个慢活儿,方法上可以是看经典原著、学习视频分享或是用高级语言实现。重要的是心态,能平心静气,不设预期,保持热情;另外,如果你有个可以分享的兴趣小组,那么恭喜你。因为学习书籍或看paper的过程其实挺枯燥的,但如果有分享的动力你可以走的更远。
实践
都知道实践出真知,可实践往往也很残酷。因为需求和约束多如牛毛,问题需要你来发现,留给你的时间窗口又很短暂。也就是,算法是一个偏确定性、有适用边界、标准化的事情;而业务则是发散的、多目标的、经验驱动的事情。
你首先是需要有双发现的眼睛,找到那个最值得发力的点,这个需要数据分析配合业务经验,剥丝抽茧留下最主要的优化目标、约束条件,尽量的简化问题;其次是有一张能说会道的嘴,要不然业务怎么愿意给你这个时间窗口让你尝试呢;最后是,在赌上你的人设之后,需要尽快在这个窗口期做出效果,在这个压力之下,考验你算法基本功的时候就到了。
结语
最后,让大家猜个谜语:它是一个贪心的家伙,计算复杂度不大,可以动态的做特征选择,不论特征是离散还是连续;它还可以先剪枝或后剪枝避免过拟合;它融合了信息熵的计算,也可以不讲道理的引入随机因子;它可以孤立的存在,也完全可以做集成学习,还可以配合LR一起来解决特征组合的问题;对小样本、正负样本不均、在线数据流的学习也可以支持;所得到则是有很强可解释性的规则。它,就是决策树。
每一个基础算法,都好比是颗带有智慧的种子,这不是普通的锦上添花,而是石破天惊的原创思维。有时不妨傻傻的回到过去的年代,伴着大师原创的步伐走一走,这种原创的智慧对未来长期的算法之路,大有裨益。神经网络从种下到开花,将近50年;贝叶斯也正在开花结果的路上。下一个,将会是谁呢?





